
When developers work with AI coding agents, they inevitably need information that exists outside the codebase. API documentation, Stack Overflow answers, GitHub issues, framework tutorials: the web remains the authoritative source for much of what developers need to know. Understanding what AI agents search for reveals both the capabilities and limitations of current agentic systems.
We asked Droid to analyze its own search behavior across 780,000 tool calls, and it took it from there: writing the SQL queries, building a classification pipeline, generating embeddings, and building the visualization below. The results reveal how agents think: they discover broadly with search, then retrieve specifically with fetch, mirroring how humans research unfamiliar topics. Documentation and learning materials dominate, with three quarters of all queries directly related to software development.
Drag to rotate, scroll to zoom. Each point is a query, positioned using embeddings that Droid generated and reduced to 3D. Similar queries cluster together naturally.
Methodology
The entire analysis pipeline was built by Droid within Factory sessions. Starting from "analyze our web search data," the agent proposed the analytical approach, wrote BigQuery SQL to extract a sample of 780,000 web searches, designed a classification schema, and built a parallel processing pipeline using droid exec to classify 10,000 sampled queries. It generated text embeddings via OpenAI's API, ran UMAP dimensionality reduction for the 3D visualization, and produced every chart using matplotlib styled to our design system.
This analysis used aggregated, anonymized data collected from API endpoint logs for our WebSearch and FetchUrl tools. The data captures only the parameters passed to these calls (search queries and URLs), stripped of any session context, user identifiers, or surrounding conversation. No individual sessions or users are identifiable in the statistics presented here.
The Dataset
Factory provides two tools for accessing external information during coding sessions. WebSearch performs general web queries, returning relevant results that the agent can use to inform its responses. FetchUrl retrieves specific URLs, allowing direct access to documentation pages, GitHub repositories, raw files, and API references.
The Information Landscape
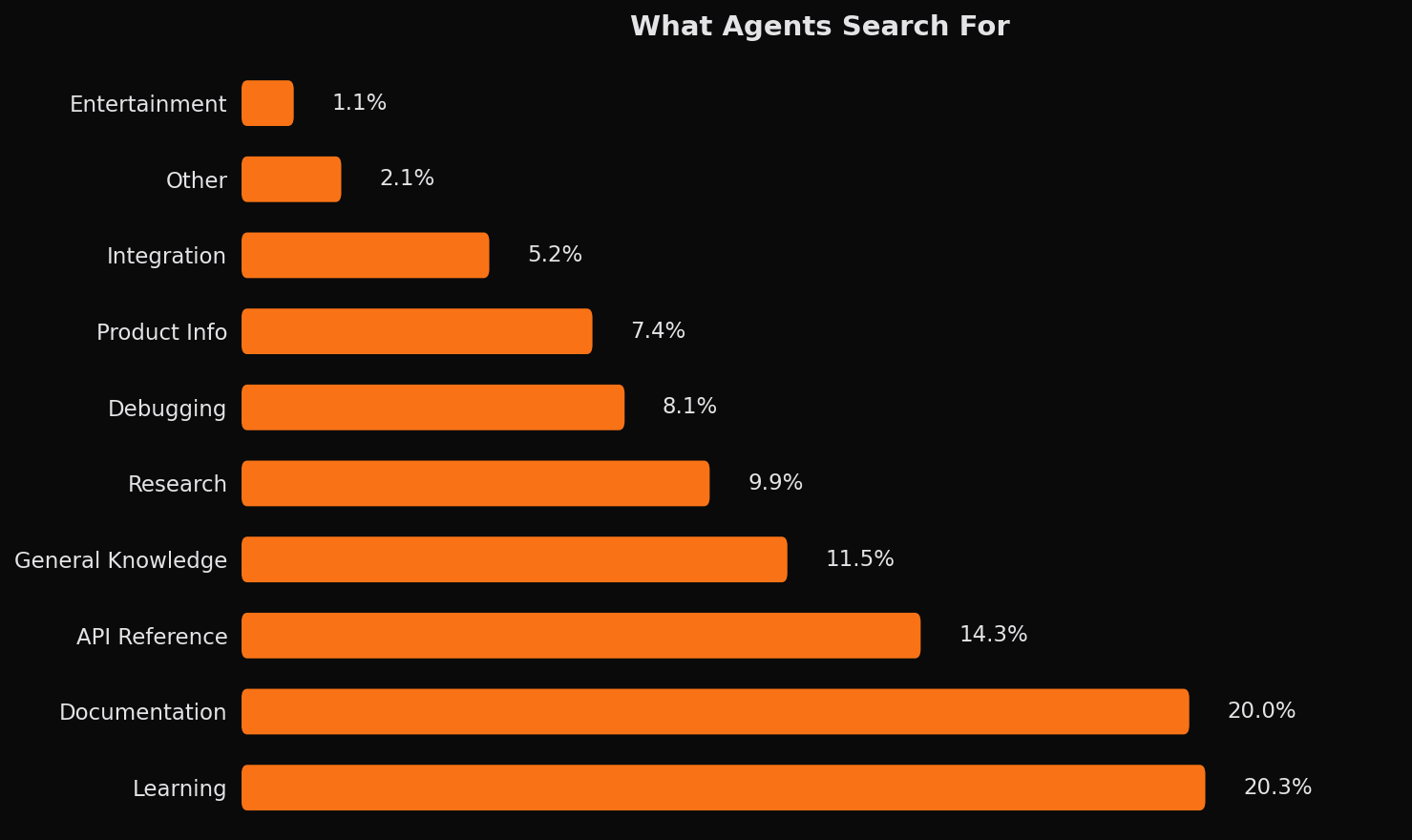
The distribution of query categories reveals that AI coding agents are fundamentally information retrieval systems. Learning materials and documentation together account for 40% of all queries, with API references adding another 14%. This concentration makes intuitive sense: when agents encounter unfamiliar territory, they reach for external knowledge to fill gaps in their training data.
Documentation queries encompass official library docs, framework references, and platform guides. These are targeted lookups where the agent knows what it needs and retrieves the authoritative source. Learning queries are more exploratory: tutorials, how-to guides, best practices articles, and conceptual explanations. The distinction matters because it suggests two distinct modes of agent behavior during coding sessions.
General knowledge queries represent non-development questions that arise during work. These include news lookups, historical facts, geographic information, and other queries unrelated to the coding task at hand. Their presence indicates that users treat AI agents as general-purpose assistants, not purely coding tools, and the agent responds accordingly.
Debugging and integration queries reflect the problem-solving nature of development work. Error messages get searched, Stack Overflow gets consulted, GitHub PRs get reviewed. The agent autonomously gathers context when troubleshooting, extending what it can accomplish without asking the developer for help.
GitHub and Factory: The Dominant Domains
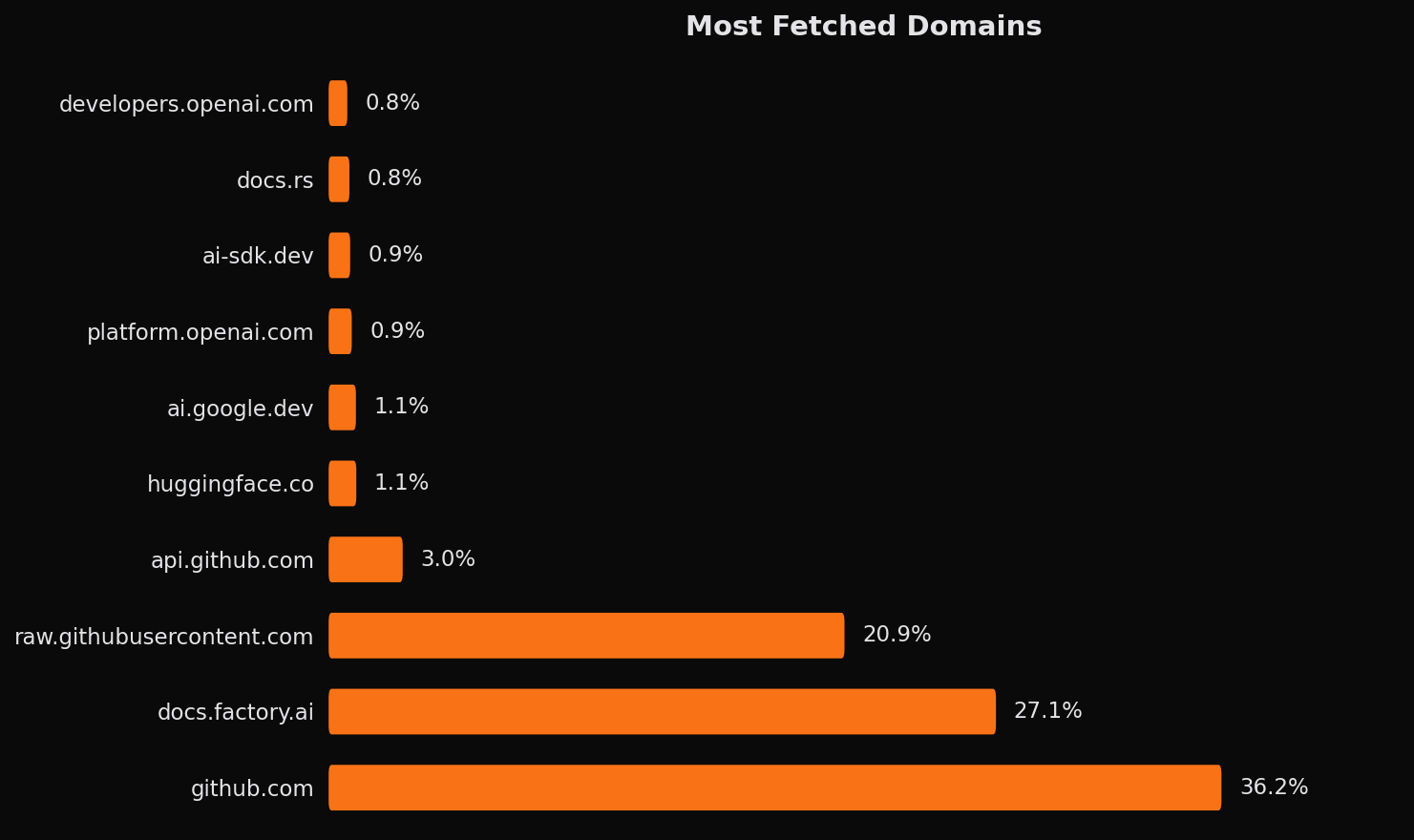
When we examine FetchUrl patterns specifically, a clear hierarchy emerges. GitHub dominates with the most fetches to github.com and raw.githubusercontent.com for direct file access. This reflects the centrality of GitHub to modern development workflows: agents constantly pull in repositories, issues, pull requests, and source files to understand the broader context of what they're working on.
The second most fetched domain is docs.factory.ai. Factory's agent automatically retrieves its own documentation when users ask capability questions, allowing Droid to answer questions about its own features, configuration options, and integrations.
The remaining top domains paint a picture of the modern development stack: Hugging Face for ML models, Google AI and Vercel AI SDK for LLM integration, arxiv for research papers, and docs.rs for Rust documentation. Each domain represents a cluster of related queries from developers working in that ecosystem.
The Search-Fetch Pattern
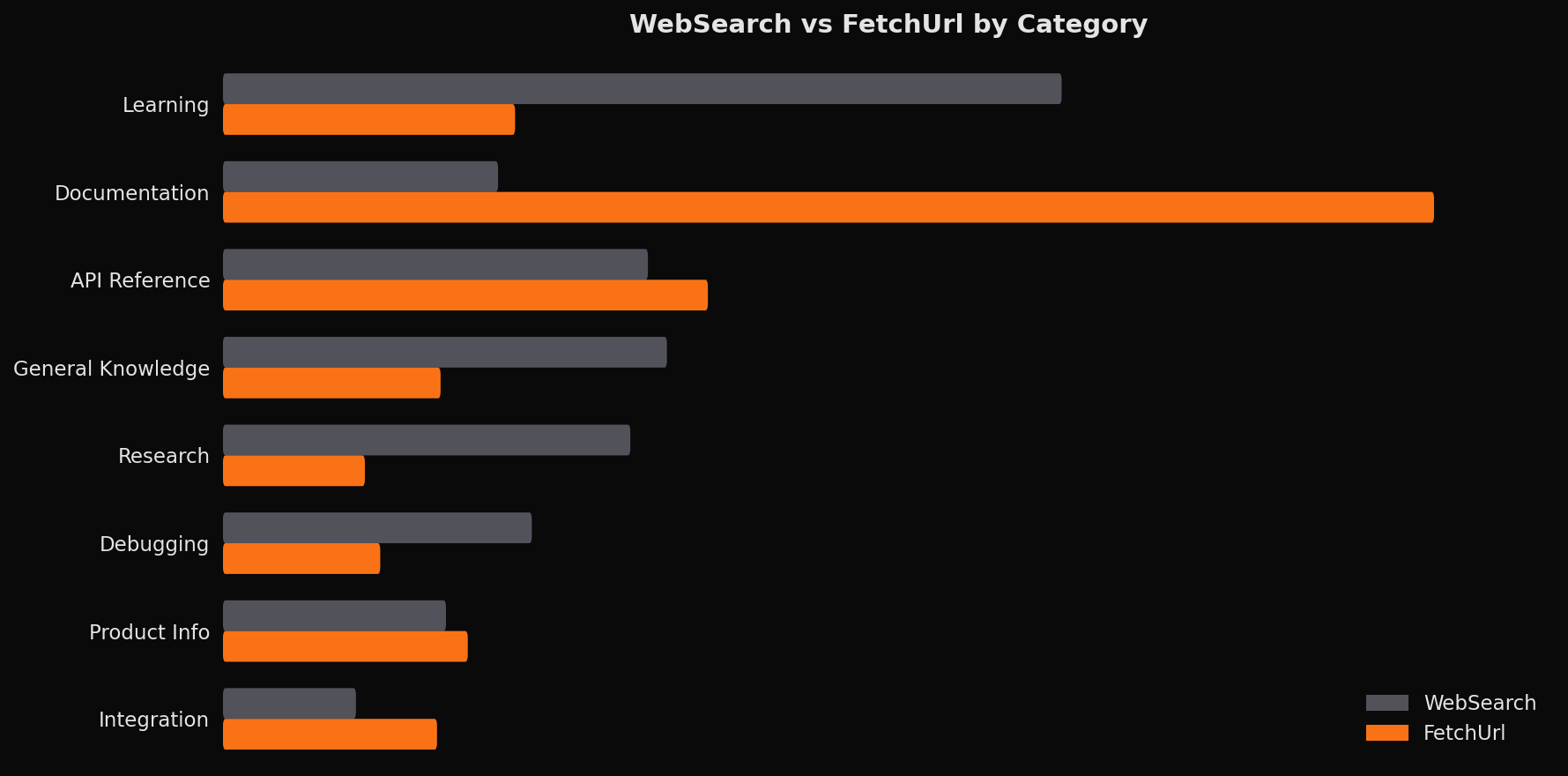
WebSearch and FetchUrl serve complementary roles that become clear when examining their usage patterns. WebSearch accounts for roughly two-thirds of tool calls and skews toward exploratory use: learning, research, and general knowledge. FetchUrl represents the remaining third and concentrates heavily on documentation and API references.
This pattern suggests a common agent workflow: WebSearch to locate relevant resources, then FetchUrl to retrieve specific pages for detailed reading. The agent's behavior shifts from discovery to retrieval as the information need becomes more precise. Optimizing this loop by caching frequently accessed documentation, pre-loading common framework references, or biasing toward known-good sources could meaningfully improve session efficiency.
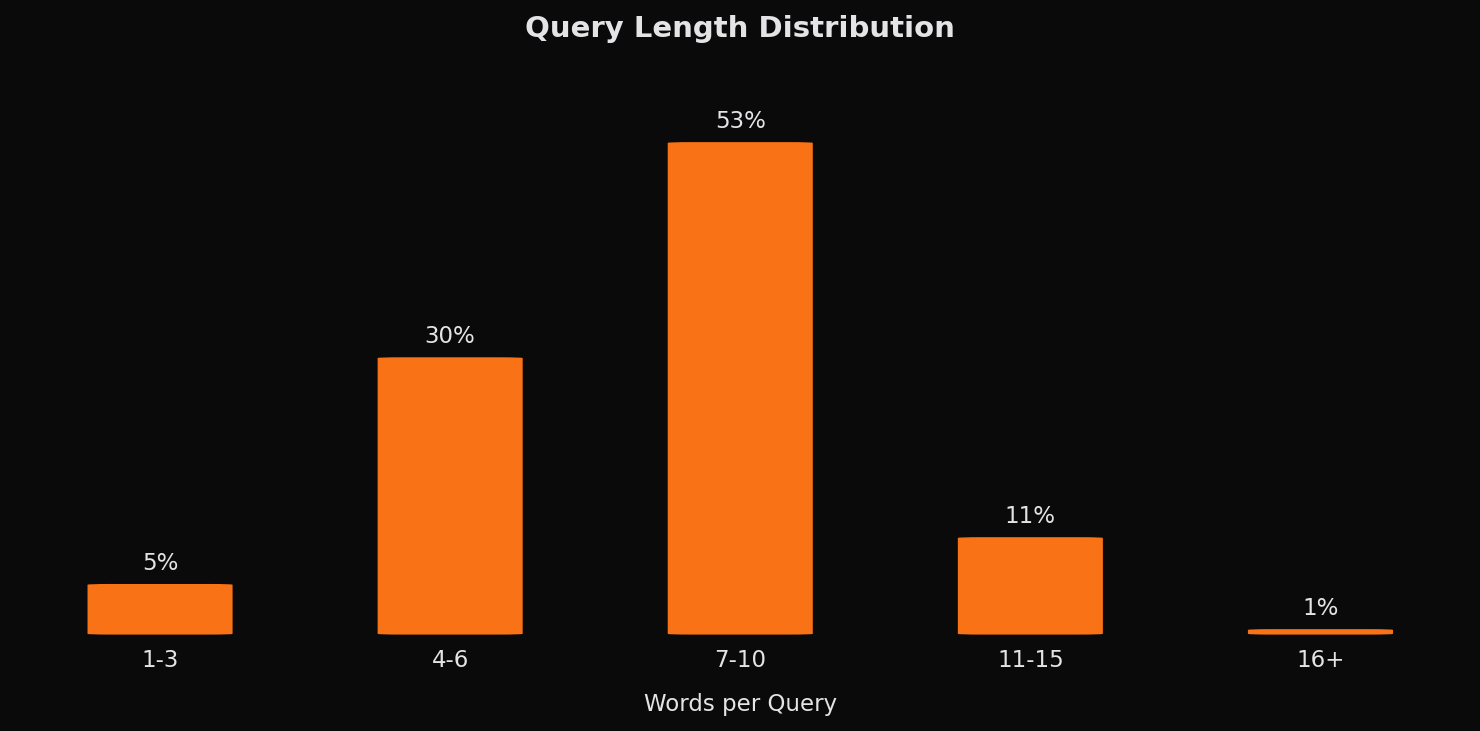
The query length distribution supports this interpretation. WebSearch queries average around 7-8 words, with most falling in the medium-length range. These are specific enough to yield relevant results but open enough to allow for discovery. Very short queries are uncommon, and verbose queries are rare.
Development Focus
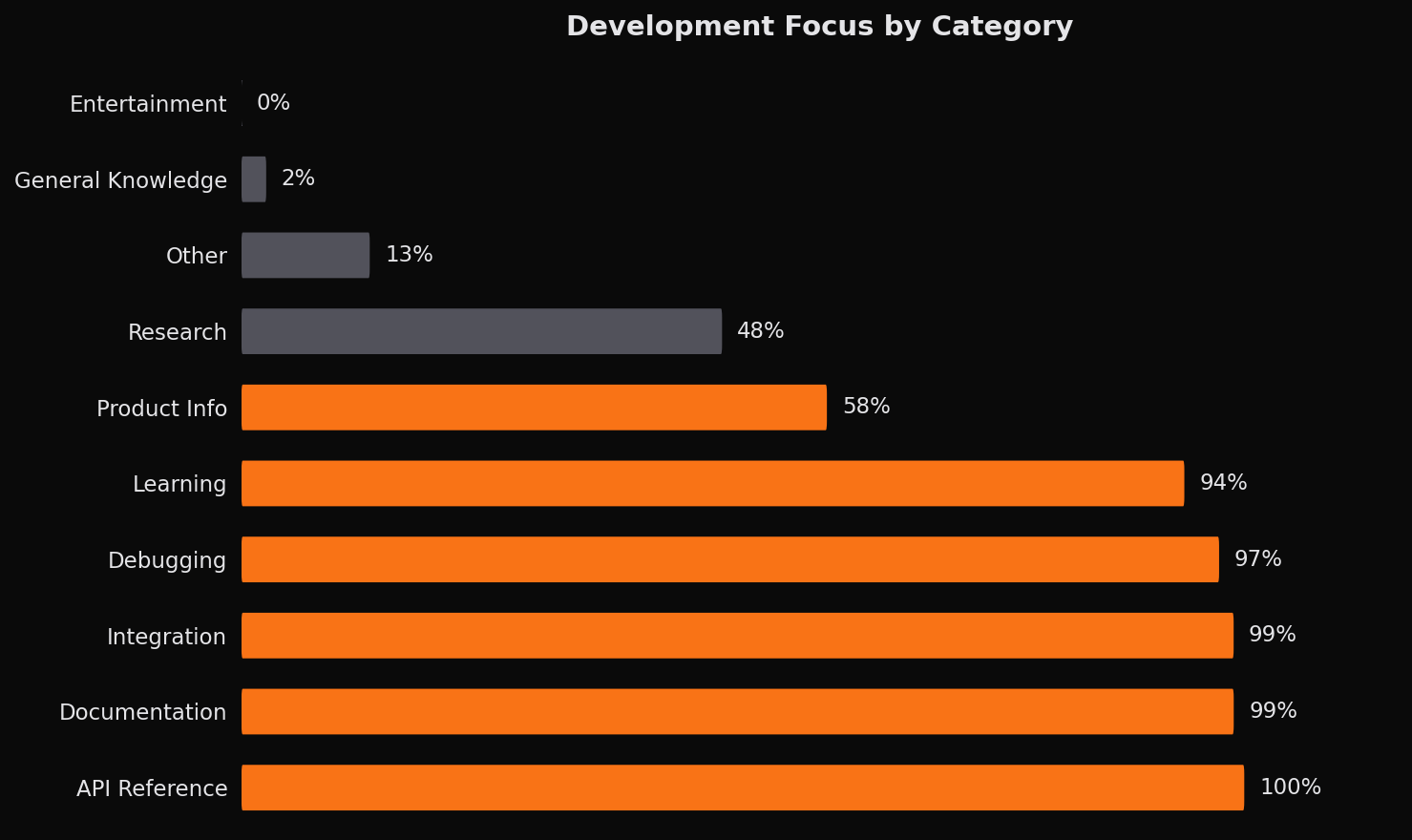
Three quarters of all queries relate directly to software development. This proportion varies dramatically by category. API Reference and Integration queries are essentially 100% development-related since these categories exist only in a development context. Documentation and Learning hover around 95-99% development focus, reflecting their primary use for technical knowledge acquisition.
The categories with lower development ratios tell their own story. Product Info splits roughly 60/40 between development (pricing for APIs, feature comparisons for tools) and non-development (general product research). Research divides evenly between technical research (GitHub repositories, academic papers on algorithms) and general research (news, analysis, reports). General Knowledge is predominantly non-development, representing the general-purpose assistant usage that occurs even in coding-focused sessions.
This distribution validates that agents stay focused on the task at hand during coding sessions. The 25% of non-development queries typically represent brief diversions or background research tangentially related to the task, rather than extended off-topic searching.
The Language Landscape
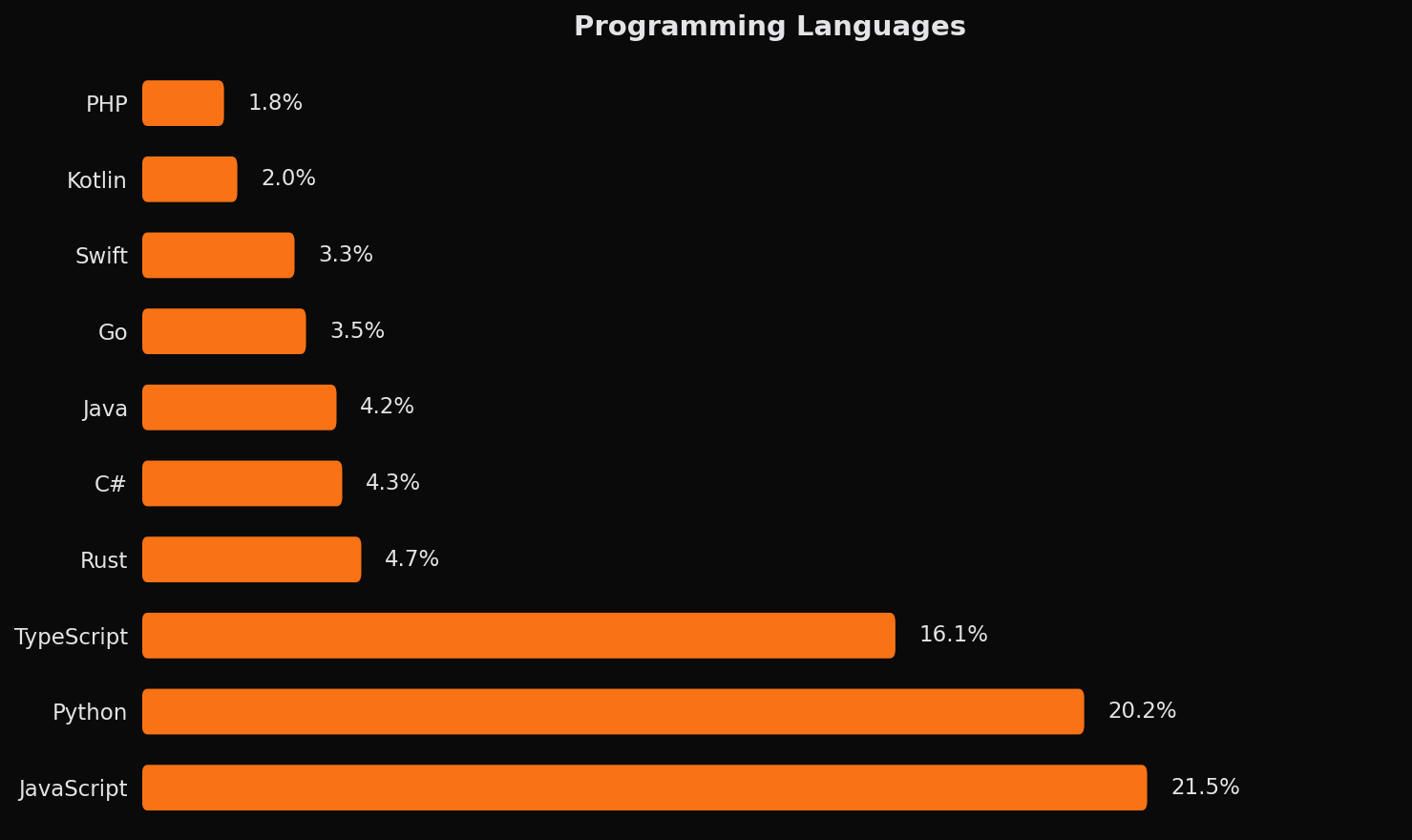
JavaScript and Python together account for nearly half of language-specific queries, reflecting their dominance in contemporary development. TypeScript adds substantially more, bringing the JavaScript ecosystem to the largest share of all language-tagged queries. This concentration aligns with broader industry trends toward web development and Python-based AI/ML work.
More interesting are the languages that punch above their market weight. Rust appears frequently despite representing a much smaller share of overall development. This suggests that AI coding tools attract systems programmers working on performance-critical applications, a demographic likely to benefit from AI assistance given Rust's notorious learning curve.
Framework-specific queries are common throughout the data. Agents don't just search for "JavaScript async await"; they search for "React useEffect cleanup" or "Next.js API routes." This level of specificity has implications for how we might optimize search and documentation retrieval.
Implications for Agent Design
These patterns suggest several directions for improving AI coding agents. The search-fetch loop is fundamental to how agents gather information: they discover broadly, then retrieve specifically. Systems that understand this pattern, maintaining context about what has been accessed and biasing toward authoritative sources, will outperform those that treat each tool call independently.
The prevalence of framework-specific queries points to another opportunity. Agents don't search for generic language questions; they search for "React useEffect cleanup" and "Next.js API routes." Built-in knowledge of common frameworks and their documentation structures will produce better results than generic web search.
GitHub deserves special attention. With GitHub representing the single largest category of fetched URLs, dedicated integration that understands repository structure, parses issues and PRs, and navigates code search is not optional for serious coding agents.
An AI agent studying its own information-seeking behavior, using the same capabilities it was analyzing, to understand how it thinks.

