Droid: The #1 Software Development Agent on Terminal-Bench
By Abhay Singhal, Leo Tchourakov, Daniel Flaherty, Stepan Bedratiuk - September 25, 2025 - 8 minute read -
Share
With a score of 58.75%, Droid sets the new state-of-the-art on Terminal-Bench. Agent design, not just choice of model, is the decisive factor as we achieve leading performance on every model.
Droid: The #1 Software Development Agent on Terminal-Bench
With a score of 58.75%, Droid sets the new state-of-the-art on Terminal-Bench. Agent design, not just choice of model, is the decisive factor as we achieve leading performance on every model.
Terminal-Bench
Terminal‑Bench is an open benchmark that measures AI agents' ability to complete complex end‑to‑end tasks in a terminal environment. The Core set (v0.1.1) has 80 human‑verified, Dockerized tasks spanning coding, build/test and dependency management, data and ML workflows, systems and networking, security, and core CLI workflows. Some examples include modernizing a Fortran build process, configuring a git web server, training RL agents and text classifiers, resolving Conda environment dependency conflicts, and scrubbing a repo of secrets. Each task is time-boxed and only considered resolved when all post‑run tests pass. The benchmark reports the task‑resolution rate.
As a software development benchmark, Terminal-Bench evaluates more than just coding ability. Each task requires the agent to comprehensively reason, explore a new environment, accurately complete the specification, and robustly validate its solution within the time limit. This breadth and rigor make it a good proxy for agentic performance in production.
Results
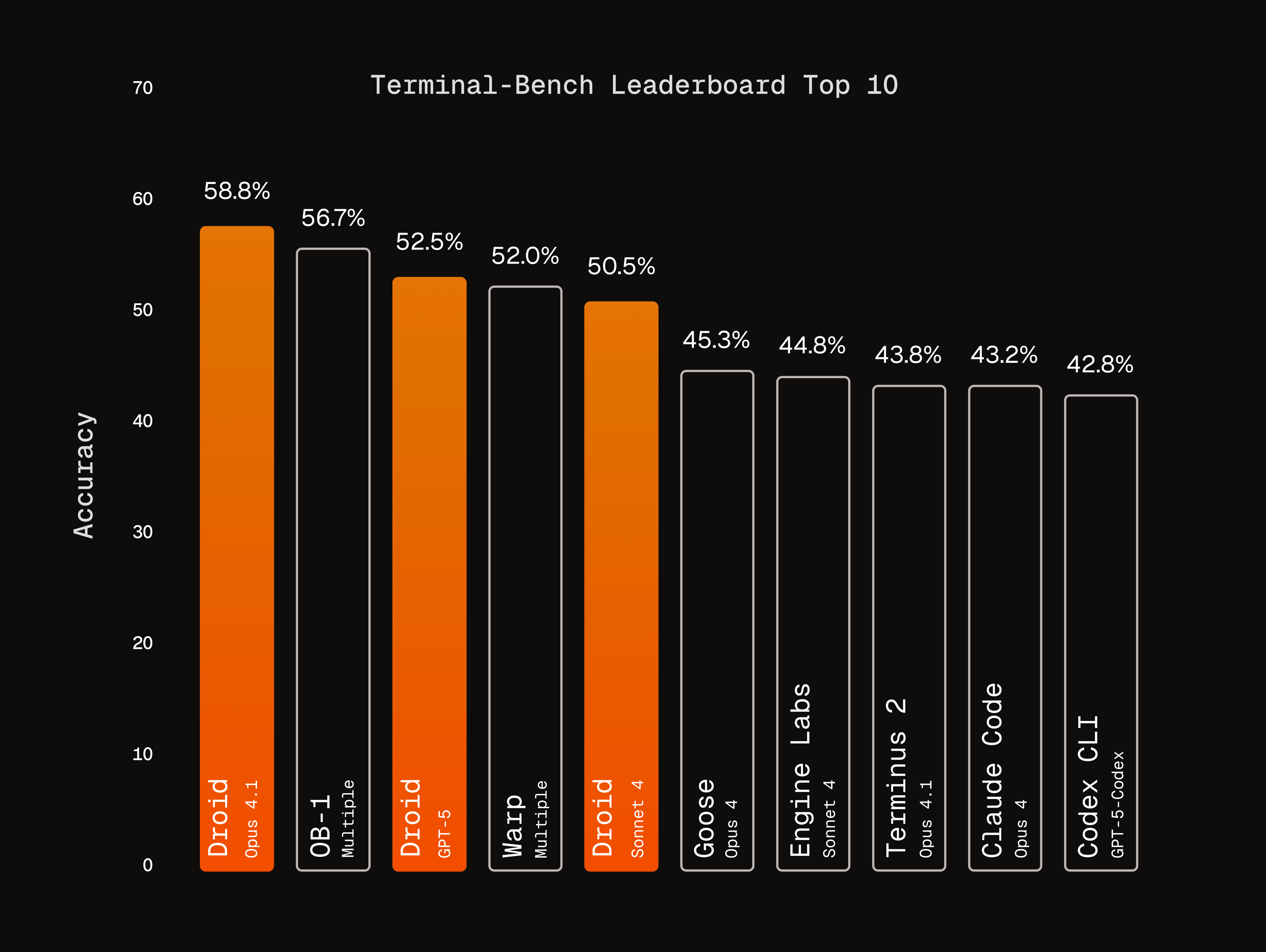
Figure 1: Top 10 Agents on Terminal-Bench Leaderboard with Models
Droid achieves 58.8% on Terminal-Bench, placing first among all agents. Factory agents occupy three of the top five positions—with Opus 4.1 (no thinking) (58.8%), GPT-5 (medium reasoning) (52.5%), and Sonnet 4 (no thinking) (50.5%). All three of our single-model configurations surpass every other single-model agent by significant margins, and with Opus 4.1 and GPT-5, Droid exceeds multi-model agents' performance, achieving these results while preserving developers' freedom to choose their preferred model.
Agent design drives performance for all models
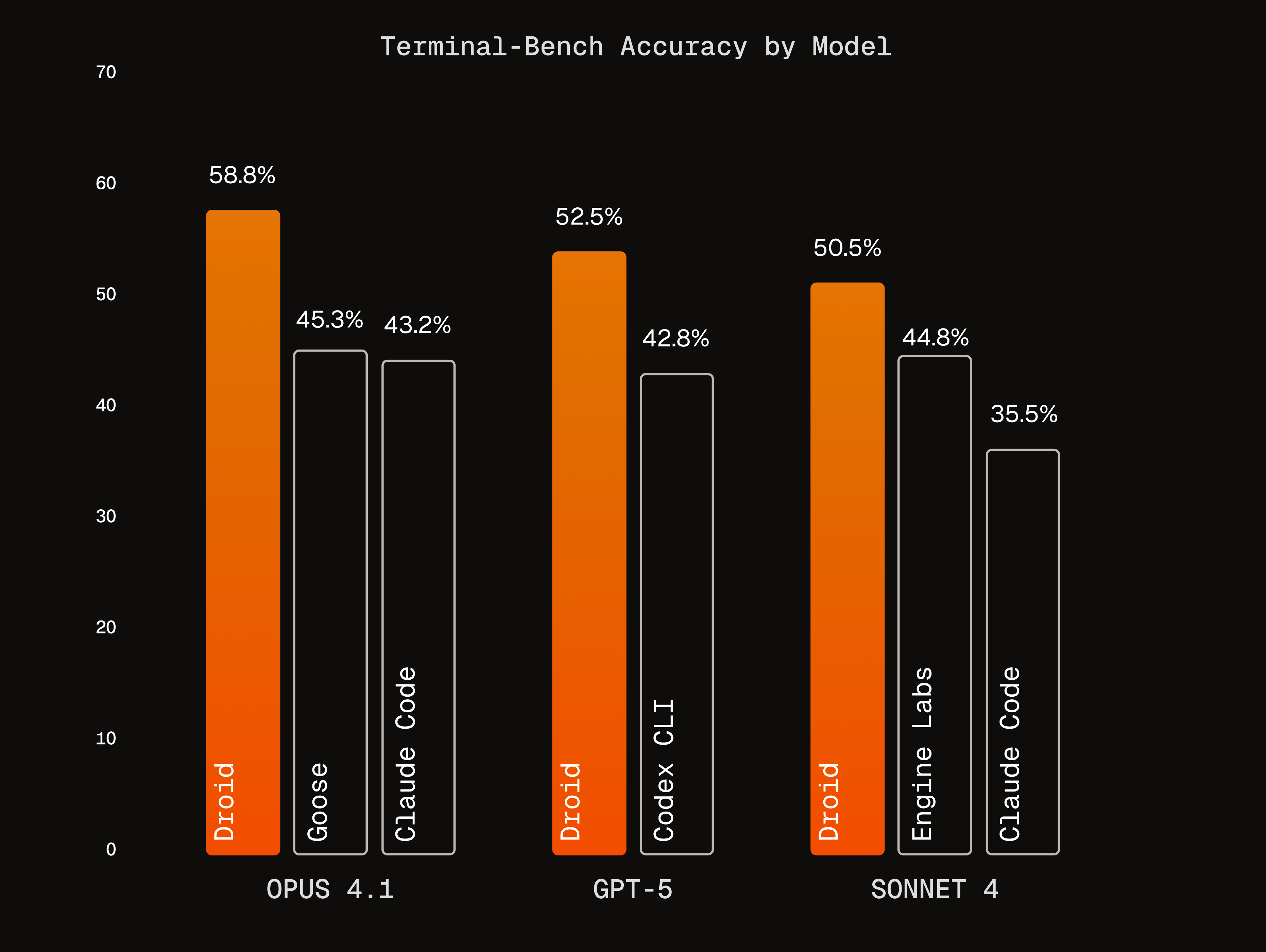
Figure 2: Terminal-Bench accuracy across top-ranked agents per model
Droid's model-agnostic agent design drives state-of-the-art performance for all frontier models. Although models ultimately drive agentic capabilities, we find that the right agent framework can lead to greater improvements than model selection. The combination of prompting and tool design, systematic environment exploration, and speed optimizations enables cheaper models to outperform more expensive ones: Droid with Sonnet outperforms all other agents using Opus.
Furthermore, Droid extracts more capability from each model than the labs' own agents: Droid with Opus (58.8%) and Sonnet (50.5%) beats Claude Code with Opus (43.2%), and Droid with GPT-5 (52.5%) tops Codex CLI (42.8%). These results, combined with improved performance relative to multi-model agents, suggest that there is more headroom for improved agentic performance with a single driving model.
Agentic system design
While an agent consists of a loop, an LLM, and tools at its core, achieving reliable end-to-end completion of complex real-world tasks presents significant challenges. We examine design considerations that emerged from developing production agentic systems, focusing on three areas: hierarchical prompting strategies, model-specific optimizations, and tool design principles.
1. Hierarchical prompting for agentic models
The rapid evolution of new generation models has fundamentally transformed our approach to prompting. The emergence of advanced agentic models (notably Sonnet 3.7 and o3) has forced us to rethink how we guide models in extended multi-turn conversations. We have found that these models exhibit recency bias by prioritizing recent context over system-level instructions for low-level, nuanced details over long agent trajectories.
This behavioral pattern led us to develop a three-tier prompting hierarchy:
Tool Descriptions: High-level specifications defining tool capabilities and usage patterns
System Prompts: Behavioral guidelines establishing agent high-level objectives and constraints
System Notifications: Contextually-injected user-level messages providing critical, time-sensitive guidance
The system notifications tier proved particularly crucial. By injecting low-level operational details at appropriate conversation points, we achieve fine-grained control over model behavior, enabling rapid error recovery and task-specific adjustments without overwhelming the system prompt.
2. The necessity of model-specific architectures
Supporting multiple foundation models while maintaining optimal performance is a key product requirement. Despite similar capabilities, flagship models from different providers exhibit significant operational divergences.
Consider file editing: one provider's model is designed to use FIND_AND_REPLACE style operations, while another prefers V4A diff formats. Path handling varies similarly; some models default to relative paths while others require absolute paths for reliable execution.
These differences extend beyond preferences to fundamental behavioral patterns. Our solution embraces this heterogeneity: a modular architecture sharing core components while allowing model-specific adaptations. This design philosophy acknowledges that extracting peak performance requires understanding and accommodating each model's inherent tendencies rather than forcing uniformity.
3. Minimalist tool design principles
Tool reliability emerged as the primary bottleneck for end-to-end task completion. Our analysis revealed that complex tool schemas exponentially increased error rates, with cascading effects on overall system performance.
We adopted a minimalist approach:
Strictly limiting the tool repertoire to essential operations.
Simplifying input schemas to reduce ambiguity.
Creating model-specific tool scaffolding when behavioral differences warranted it.
This strategy yielded substantial improvements. By reducing individual tool call error rates, we observed multiplicative gains in full-task completion rates.
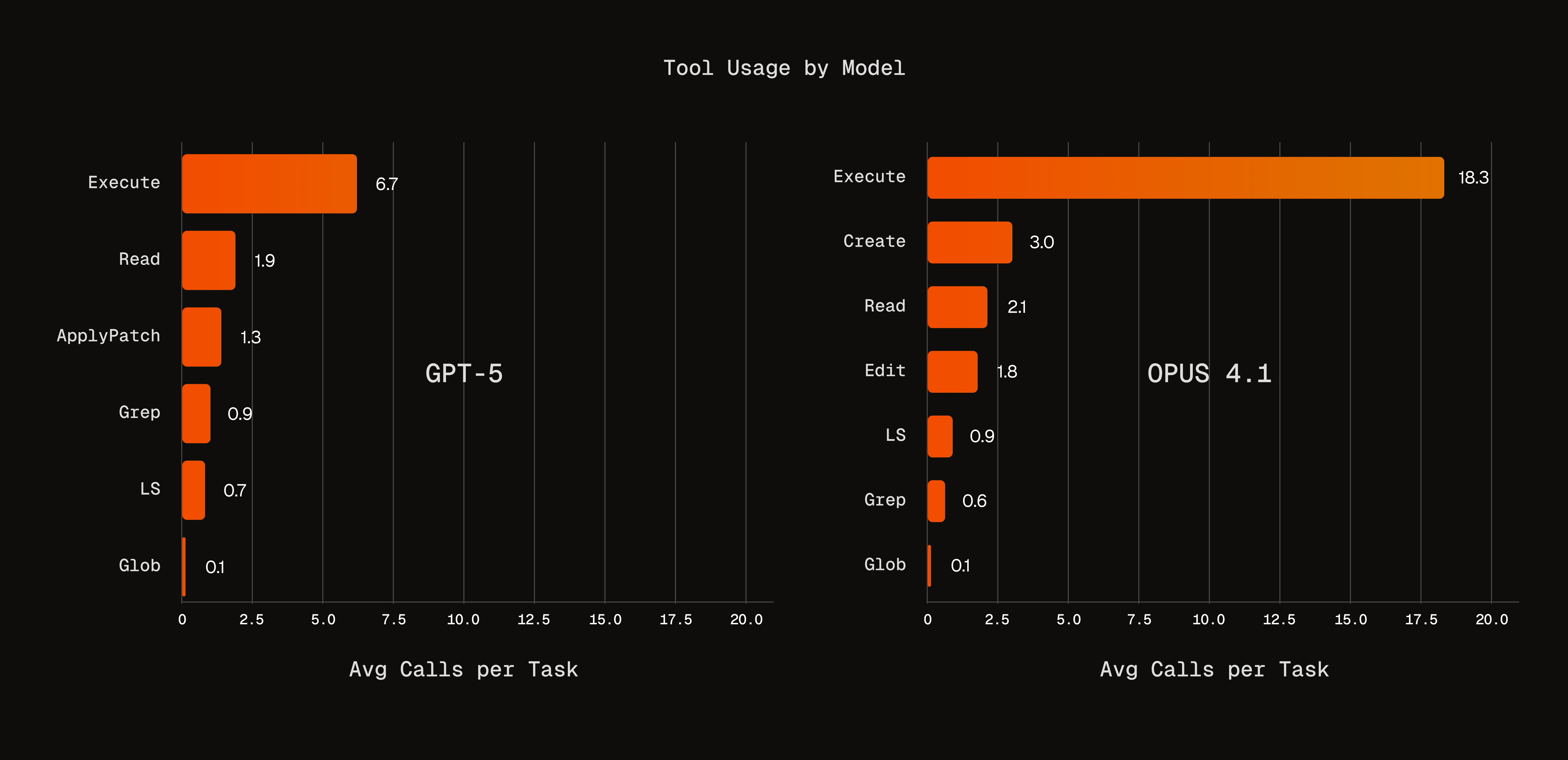
Figure 3: Comparing Tool Usage Patterns of GPT-5 and Opus 4.1 Across Terminal-Bench Runs
System and environment awareness
Understanding the environmental context is essential to many real-world and benchmark tasks. This includes understanding the context of available programming languages, git repo contents, environment variables, and running processes.
Droid streamlines environmental understanding by bootstrapping each new session with a broad range of salient system information. This not only helps save time and tokens but also improves success rates on the more complex tasks that require troubleshooting system-wide issues by nudging Droid to explore alternatives it wouldn't have considered otherwise. The presentation of this information matters. We've found that presenting this system information as shell command output helped Droid avoid redundantly reissuing similar commands.
Optimizing for speed
Droid has been tuned to complete its tasks faster. This was key to completing many Terminal-Bench tasks, which have aggressive timeouts. More efficient environment discovery is just one of many optimizations we did. Other impactful changes include:
Making the LLMs aware of the tool and session run time. This gives the LLM a concrete sense of tool runtime so it can avoid repeating slow operations, choose faster alternatives, and set timeouts more intelligently. The runtimes are only added when they exceed certain thresholds to avoid polluting the context window with low signal information.
More efficient tool implementations. For example, implementing the grep tool using ripgrep helps Droid work with large repos more efficiently.
Tuning default tool timeouts. Counterintuitively, using short default timeouts led to better average performance by cutting long, unproductive waits and failing fast. Droid still explicitly opts into longer timeouts when it knows a command needs more time; the short default timeout just nudges toward faster iteration.
Planning
Giving the agent a tool to create and update a concise plan improves an agent's ability to stay organized and on track throughout the duration of task execution. As steps of the plan are completed, having a tool call which crosses off the most recent step while simultaneously marking the next item as in progress, inserts an explicit reminder of what work has been done, as well as what the agent should work on next at the very end/newest section of the context window, which LLMs have been found to especially pay attention to [2].
In addition to better long context coherence, it gives humans an easy way to track and supervise an agent's progress, saving them time otherwise spent meticulously combing through a potentially very long session.
Supporting long-running processes
Many real workflows (and Terminal‑Bench tasks) require starting services, such as servers, that outlive the Droid process. Droid has a controlled background‑execution primitive so the agent can start a process, keep working, and leave it running for tests to hit later. For security and performance, backgrounding is opt‑in via settings and filtered to block dangerous or resource‑intensive commands, and every spawned process is tracked for later cleanup.
Terminal-Bench Deep Dive
Methods
For each model, we ran Terminal-Bench five times and submitted all runs. We integrated into the harness via a custom AbstractInstalledAgent and ran all benchmark runs on Ubuntu machines. For each task, we ran Droid in a non-interactive task mode with all permissions skipped (as the environment was sandboxed) with the specification passed in as the task prompt.
Model performance insights
All of the state-of-the-art LLM models available by Droid are able to solve the majority of solvable tasks, in particular, the easier and well-specified tasks. Each model offered some unique advantages. The overall best model performance came from using Claude Opus 4.1. Compared to other models, Opus 4.1 enabled Droid to solve challenging tasks that required advanced debugging.
One such example is the security-vulhub-minio task:
jsx
Access the MinIO credentials that are stored in the environment variableson the nodes and print them to the file `/app/result.txt`.MinIO is running on node1:9000.
While the task description appears to suggest looking for environment variables, the actual solution required exploiting CVE-2023-28432, a known MinIO information disclosure vulnerability. Other models seemed to lack security vulnerability knowledge and typically never discovered or attempted CVE exploitation. Droid, using Opus, on the other hand, reliably recognized and applied the vulnerability to extract the credentials.
Another interesting example is cron-broken-network task.
jsx
For some reason I can't curl example.com, can you figure out why and what I should do to fix it?
Droid quickly fixes the immediate problem with curl regardless of which of LLM is used. In most cases, it can identify that this task also requires fixing a deeper root cause - simulated malware that undoes the immediate fix to curl. When using Opus 4.1, Droid is able to fix this root cause more reliably in all trials. When using other models, it can sometimes either fail to identify the deeper issue or refuse to make the necessary changes to fix it.
On the flip side, OpenAI GPT-5 and OpenAI GPT-5 Codex models demonstrated better knowledge in domains like ML model training and video editing. Their tendency to avoid more risky changes, as demonstrated by examples above, is very important in most real-world tasks. Given their drastically lower cost compared to Claude Opus 4.1, they are the most practical choice for the majority of use cases with Droid.
Try Factory
With Factory, developers can choose to use any model, including their own custom ones, and get the best possible results across a wide variety of tasks without changing their workflows. Running Droids locally and in the cloud, they can operate at significantly higher velocity by delegating work at scale. The final result, whether it's a set of PRs, configured infrastructure, or an incident investigation, will be well-researched, accurate, extensively verified, and thus easy to review and push to prod.
Droid is available across all interfaces today. Try it out with a free month at app.factory.ai.
As we look forward to the future of software engineering, we remain committed to advancing the frontier and addressing the needs of developers. We are exploring various avenues to enable new capabilities for Droid and further embed it in the software development life cycle. Some of these include:
Multi‑agent architectures and orchestration
Running thousands of Droids in parallel fundamentally changes what's possible in software development. We're exploring patterns for decomposing large projects across specialized agents: splitting complex migrations, racing different solution approaches, and cross-verifying critical changes. The orchestration design space is rich: determining when to parallelize versus sequence, how agents coordinate without overwhelming context windows, and how to converge multiple solution paths into a single shippable result. Equally important is the human interface—how developers supervise, guide, and review work from agent swarms without losing visibility or control. With the right orchestration primitives, a single developer can drive the work output of an entire team.
Advanced memory and continuous learning
As Droids tackle increasingly challenging problems in larger, more complex codebases and organizations, memory must be durable and current, scoped (org/team/repo), searchable at variable granularity, and safe by default. We're also exploring fine‑tuning and reinforcement learning, so that Droid can be further optimized and tuned for more personalized and team‑specific workflows, knowledge, and patterns while preserving reproducibility, privacy, and security.
Ubiquitous droids and automation
Sharing a single brain, we are excited about making Droid ubiquitous and broadening availability across all interfaces and workflows—CLI, IDE, code review, CI/CD, terminals, and servers—with reliable background automation of software development workflows at scale.
We're hiring broadly across research, engineering, and go-to-market. If this work excites you, build the Factory with us! Apply here: https://factory.ai/company#careers
References
Terminal-Bench.terminal-bench: a benchmark for AI agents in terminal environments. Stanford × LAUDE. Available at: https://www.tbench.ai/
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv preprint arXiv:2307.03172. Available at: https://arxiv.org/abs/2307.03172.