By Factory Research - December 16, 2025 - 10 minute read -
Share
We built an evaluation framework to measure how much context different compression strategies preserve. After testing three approaches on real-world, long-running agent sessions spanning debugging, code review, and feature implementation, we found that structured summarization retains more useful information than alternatives from OpenAI and Anthropic.
When an AI agent helps you work through a complex task across hundreds of messages, what happens when it runs out of memory? The answer determines whether your agent continues productively or starts asking "wait, what were we trying to do again?"
We built an evaluation framework to measure how much context different compression strategies preserve. After testing three approaches on real-world, long-running agent sessions (debugging, PR review, feature implementation, CI troubleshooting, data science, ML research), we found that structured summarization retains more useful information than alternative methods from OpenAI and Anthropic, without sacrificing compression efficiency.
This post walks through the problem, our methodology, concrete examples of how different approaches perform, and what the results mean for building reliable AI agents.
The problem
Long-running agent sessions can generate millions of tokens of conversation history. That far exceeds what any model can hold in working memory.
The naive solution is aggressive compression: squeeze everything into the smallest possible summary. But this increases the chance your agent forgets which files it modified or what approach it already tried. It is likely to waste tokens re-reading files and re-exploring dead ends.
The right optimization target is not tokens per request. It is tokens per task.
Measuring context quality
Traditional metrics like ROUGE or embedding similarity do not tell you whether an agent can continue working effectively after compression. A summary might score high on lexical overlap while missing the one file path the agent needs to continue.
We designed a probe-based evaluation that directly measures functional quality. The idea is simple: after compression, ask the agent questions that require remembering specific details from the truncated history. If the compression preserved the right information, the agent answers correctly. If not, it guesses or hallucinates.
We use four probe types:
Probe type
What it tests
Example question
Recall
Factual retention
"What was the original error message?"
Artifact
File tracking
"Which files have we modified? Describe what changed in each."
Continuation
Task planning
"What should we do next?"
Decision
Reasoning chain
"We discussed options for the Redis issue. What did we decide?"
Recall probes test whether specific facts survive compression. Artifact probes test whether the agent knows what files it touched. Continuation probes test whether the agent can pick up where it left off. Decision probes test whether the reasoning behind past choices is preserved.
We grade responses using an LLM judge (GPT-5.2) across six dimensions:
Dimension
What it measures
Accuracy
Are technical details correct? File paths, function names, errors
Context awareness
Does the response reflect current conversation state?
Artifact trail
Does the agent know which files were read or modified?
Completeness
Does the response address all parts of the question?
Continuity
Can work continue without re-fetching information?
Instruction following
Does the response follow the probe format?
Each dimension is scored 0-5 using detailed rubrics. The rubrics specify what constitutes a 0 ("Completely fails"), 3 ("Adequately meets with minor issues"), and 5 ("Excellently meets with no issues") for each criterion.
Why these dimensions matter for software development
These dimensions were chosen specifically because they capture what goes wrong when coding agents lose context:
Artifact trail is critical because coding agents need to know which files they have touched. Without this, an agent might re-read files it already examined, make conflicting edits, or lose track of test results. A ChatGPT conversation can afford to forget earlier topics; a coding agent that forgets it modified auth.controller.ts will produce inconsistent work.
Continuity directly impacts token efficiency. When an agent cannot continue from where it left off, it re-fetches files and re-explores approaches it already tried. This wastes tokens and time, turning a single-pass task into an expensive multi-pass one.
Context awareness matters because coding sessions have state. The agent needs to know not just facts from the past, but the current state of the task: what has been tried, what failed, what is left to do. Generic summarization often captures "what happened" while losing "where we are."
Accuracy is non-negotiable for code. A wrong file path or misremembered function name leads to failed edits or hallucinated solutions. Unlike conversational AI where approximate recall is acceptable, coding agents need precise technical details.
Completeness ensures the agent addresses all parts of a multi-part request. When a user asks to "fix the bug and add tests," a complete response handles both. Incomplete responses force follow-up prompts and waste tokens on re-establishing context.
Instruction following verifies the agent respects constraints and formats. When asked to "only modify the auth module" or "output as JSON," the agent must comply. This dimension catches cases where compression preserved facts but lost the user's requirements.
Three approaches to compression
We compared three production-ready compression strategies.
Factory maintains a structured, persistent summary with explicit sections for different information types: session intent, file modifications, decisions made, and next steps. When compression triggers, only the newly-truncated span is summarized and merged with the existing summary. We call this anchored iterative summarization.
The key insight is that structure forces preservation. By dedicating sections to specific information types, the summary cannot silently drop file paths or skip over decisions. Each section acts as a checklist: the summarizer must populate it or explicitly leave it empty. This prevents the gradual information loss that occurs with freeform summarization.
OpenAI offers the /responses/compact endpoint, which produces opaque, compressed representations optimized for reconstruction fidelity. It achieves the highest compression ratios (99.3%) but sacrifices interpretability. You cannot read the compressed output to verify what was preserved.
Anthropic provides built-in context compression through the Claude SDK. It produces detailed, structured summaries (typically 7-12k characters) with sections for analysis, files, pending tasks, and current state. The key difference from Factory is the update mechanism: Anthropic regenerates the full summary on each compression, while Factory's anchored approach incrementally merges new information into a persistent summary. This affects both consistency across compressions and which details survive repeated compression cycles.
A concrete example
Consider a debugging session where a user reported a 401 error on the /api/auth/login endpoint despite valid credentials. Over 178 messages and 89,000 tokens, the assistant:
Read the authentication controller and identified JWT token generation
Examined the middleware chain and found a misconfigured CORS policy
Discovered the session store was using an expired Redis connection
Fixed the Redis connection pooling configuration
Added retry logic for transient connection failures
Ran the test suite (14 tests passing, 2 failing)
Fixed the remaining test failures related to mock setup
After compression, we ask: "Before we continue, can you remind me what the original error was that started this debugging session? Please be specific about the error code and endpoint."
Here is how each method responded:
Factory response (scored 4.8/5):
"The original error was a 401 Unauthorized response from the /api/auth/login endpoint. Users were receiving this error even when providing valid username/password combinations. The root cause turned out to be a stale Redis connection in the session store - the JWT was being generated correctly, but the session could not be persisted, causing subsequent authenticated requests to fail."
Anthropic response (scored 3.9/5):
"The session started with debugging a login failure - specifically a 401 error on the authentication endpoint. We traced the issue through the auth flow and found it was related to session storage rather than the credential validation itself."
OpenAI response (scored 3.2/5):
"We were debugging an authentication issue. The login was failing for users. We looked at several files and found some configuration problems that needed to be fixed."
The Factory response names the exact endpoint (/api/auth/login), the error code (401), and the root cause (Redis session store). The Anthropic response gets the error code and general cause but loses the endpoint path. The OpenAI response loses almost all technical detail.
This pattern repeated across probe types. On artifact probes ("Which files have we modified?"), Factory scored 3.6 while OpenAI scored 2.8. Factory's summary explicitly lists files in a dedicated section. OpenAI's compression discards file paths as low-entropy content.
How the LLM judge works
We use GPT-5.2 as an LLM judge, following the methodology established by Zheng et al. (2023) in their MT-Bench paper. Their work showed that GPT-4 achieves over 80% agreement with human preferences, matching the agreement level among humans themselves.
The judge receives the probe question, the model's response, the compacted conversation context, and (when available) ground truth. It then scores each rubric criterion with explicit reasoning.
Here is an abbreviated example of judge output for the Factory response above:
json
{ "criterionResults": [ { "criterionId": "accuracy_factual", "score": 5, "reasoning": "Response correctly identifies the 401 error, the specific endpoint (/api/auth/login), and the root cause (Redis connection issue)." }, { "criterionId": "accuracy_technical", "score": 5, "reasoning": "Technical details are accurate - JWT generation, session persistence, and the causal chain are correctly described." }, { "criterionId": "context_artifact_state", "score": 4, "reasoning": "Response demonstrates awareness of the debugging journey but does not enumerate all files examined." }, { "criterionId": "completeness_coverage", "score": 5, "reasoning": "Fully addresses the probe question with the error code, endpoint, symptom, and root cause." } ], "aggregateScore": 4.8}
The judge does not know which compression method produced the response. It evaluates purely on response quality against the rubric.
Results
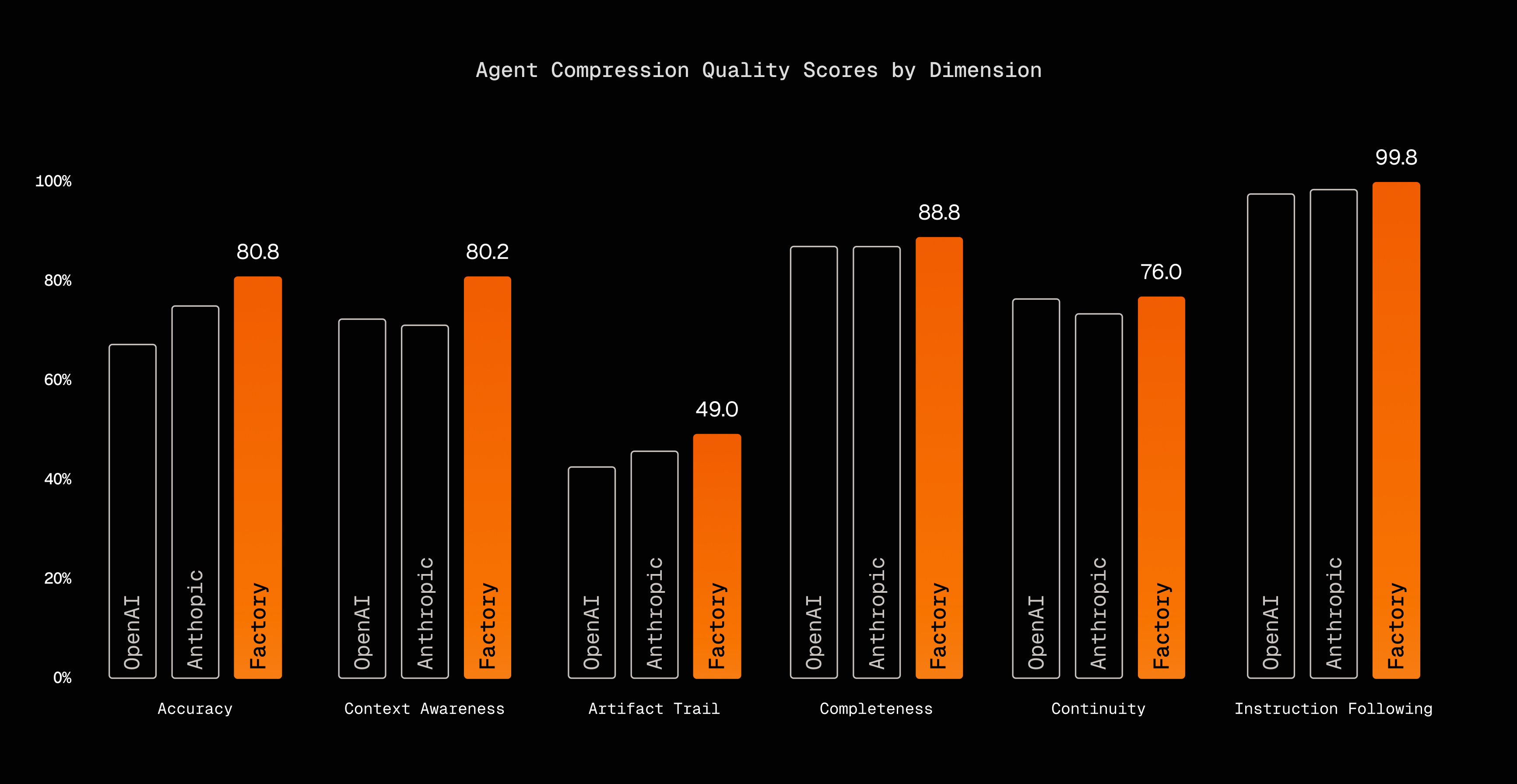
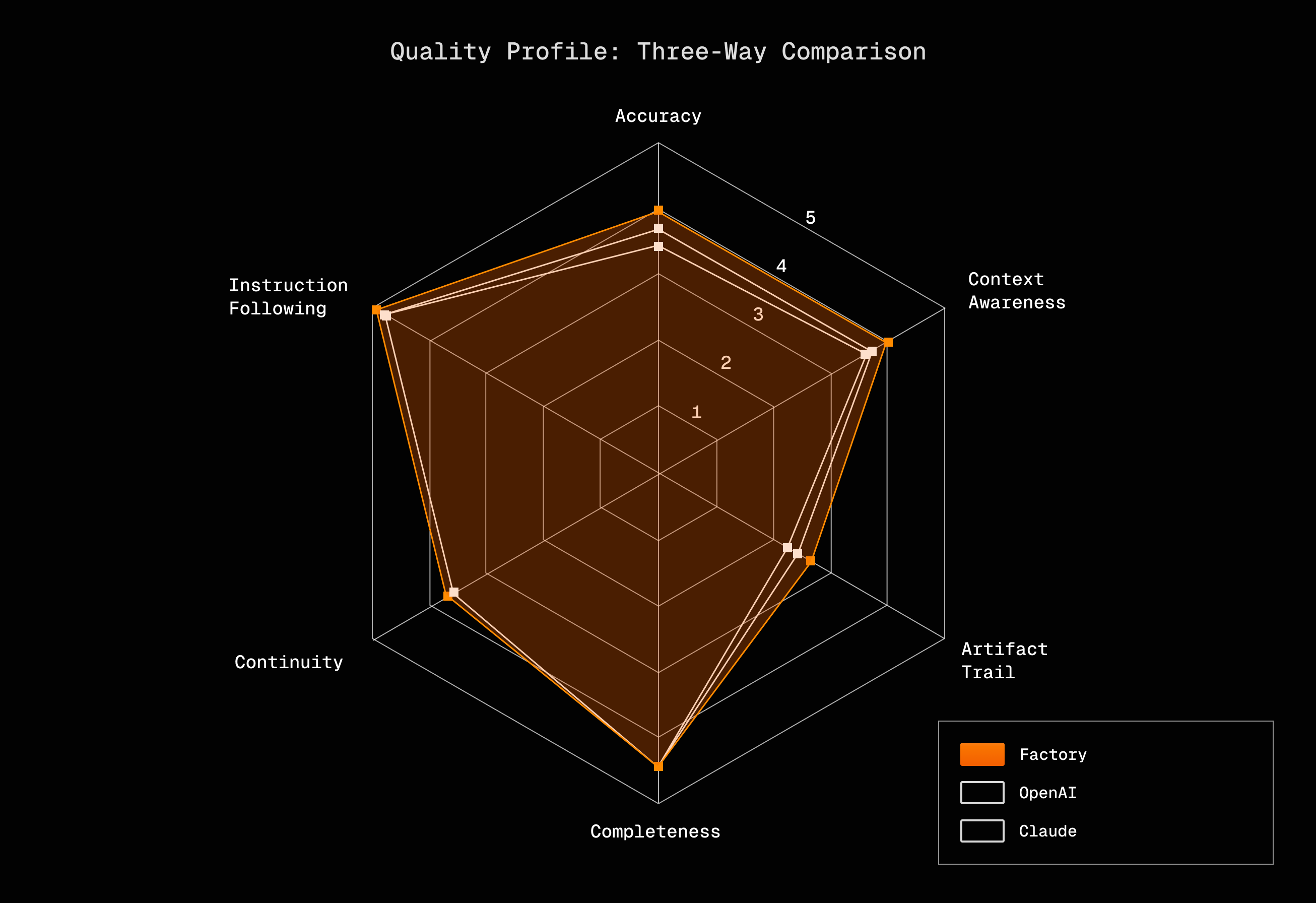
We evaluated all three methods on over 36,000 messages from production sessions spanning PR review, testing, bug fixes, feature implementation, and refactoring. For each compression point, we generated four probe responses per method and graded them across six dimensions.
Method
Overall
Accuracy
Context
Artifact
Complete
Continuity
Instruction
Factory
3.70
4.04
4.01
2.45
4.44
3.80
4.99
Anthropic
3.44
3.74
3.56
2.33
4.37
3.67
4.95
OpenAI
3.35
3.43
3.64
2.19
4.37
3.77
4.92
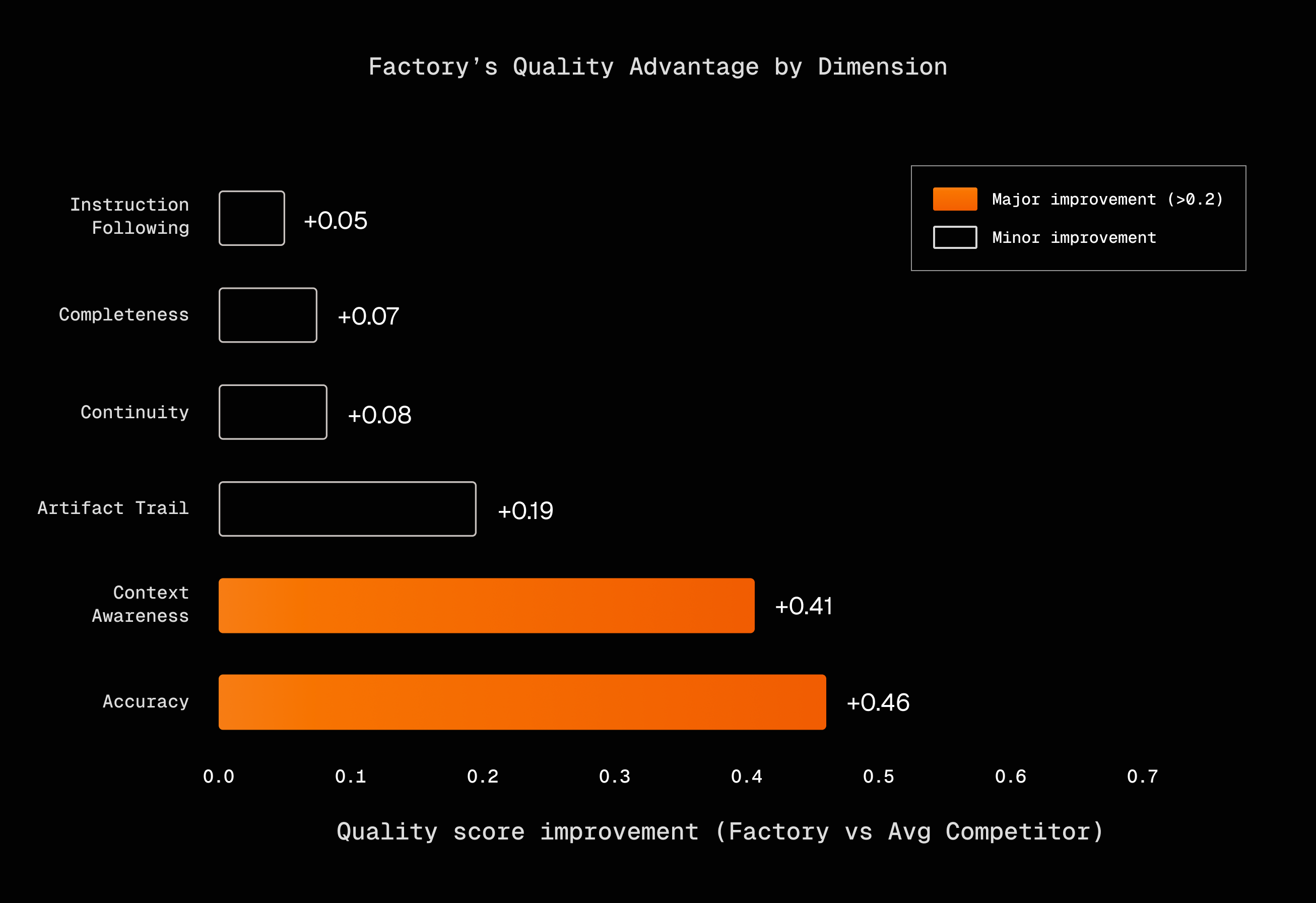
Factory scores 0.35 points higher than OpenAI and 0.26 higher than Anthropic overall.
Breaking down by dimension:
Accuracy shows the largest gap. Factory scores 4.04, Anthropic 3.74, OpenAI 3.43. The 0.61 point difference between Factory and OpenAI reflects how often technical details like file paths and error messages survive compression.
Context awareness favors Factory (4.01) over Anthropic (3.56), a 0.45 point gap. Both approaches include structured sections for current state. Factory's advantage comes from the anchored iterative approach: by merging new summaries into a persistent state rather than regenerating from scratch, key details are less likely to drift or disappear across multiple compression cycles.
Artifact trail is the weakest dimension for all methods, ranging from 2.19 to 2.45. Even Factory's structured approach struggles to maintain complete file tracking across long sessions. This suggests artifact preservation needs specialized handling beyond general summarization.
Completeness and instruction following show small differences. All methods produce responses that address the question and follow the format. The differentiation happens in the quality of the content, not its structure.
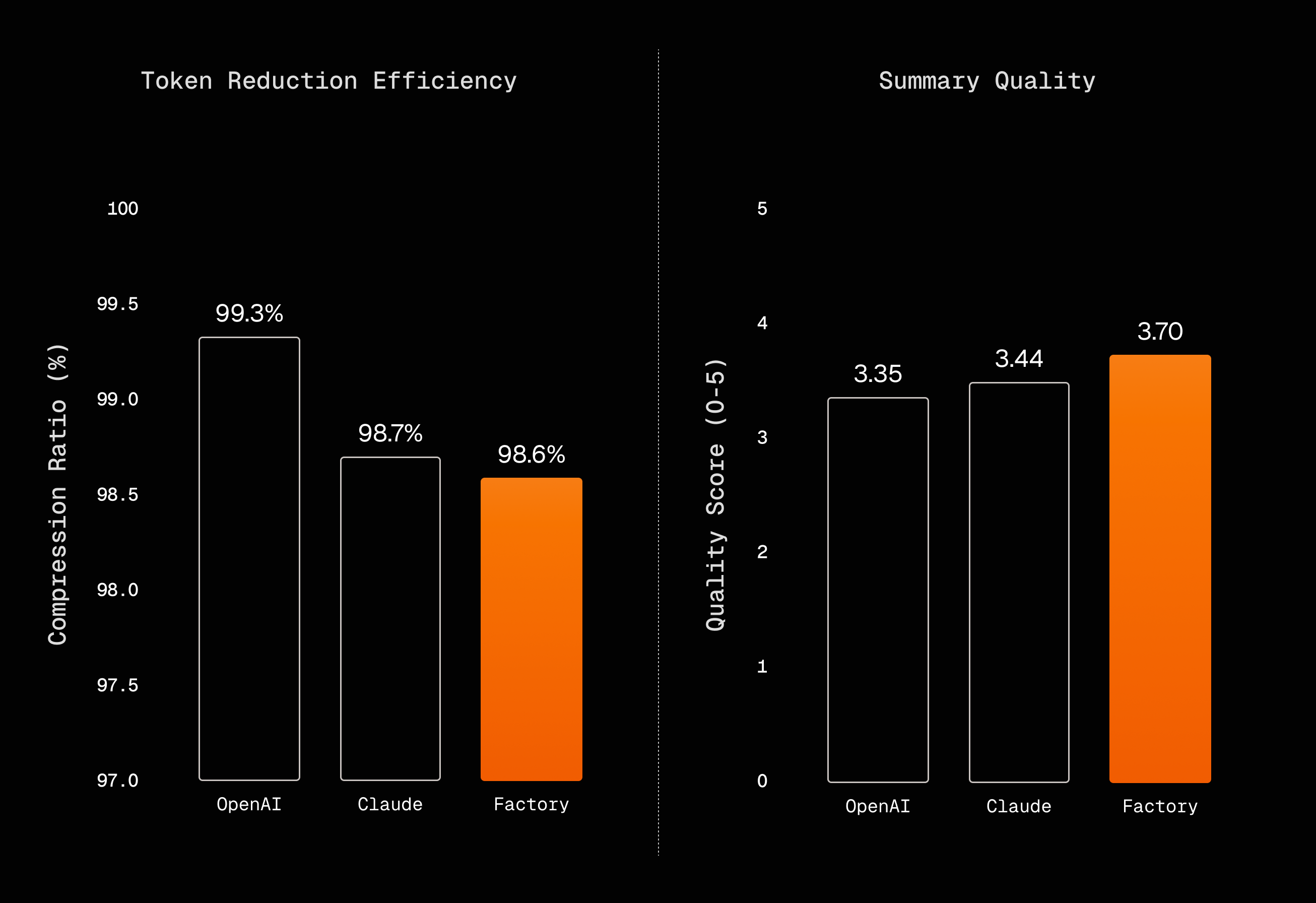
Compression ratios tell an interesting story. OpenAI compresses to 99.3% (removing 99.3% of tokens), Anthropic to 98.7%, Factory to 98.6%. Factory retains about 0.7% more tokens than OpenAI, but gains 0.35 quality points. That tradeoff favors Factory for any task where re-fetching costs matter.
What we learned
The biggest surprise was how much structure matters. Generic summarization treats all content as equally compressible. A file path might be "low entropy" from an information-theoretic perspective, but it is exactly what the agent needs to continue working. By forcing the summarizer to fill explicit sections for files, decisions, and next steps, Factory's format prevents the silent drift that happens when you regenerate summaries from scratch.
Compression ratio turned out to be the wrong metric entirely. OpenAI achieves 99.3% compression but scores 0.35 points lower on quality. Those lost details eventually require re-fetching, which can exceed the token savings. What matters is total tokens to complete a task, not tokens per request.
Artifact tracking remains an unsolved problem. All methods scored between 2.19 and 2.45 out of 5.0 on knowing which files were created, modified, or examined. Even with explicit file sections, Factory only reaches 2.45. This probably requires specialized handling beyond summarization: a separate artifact index, or explicit file-state tracking in the agent scaffolding.
Finally, probe-based evaluation captures something that traditional metrics miss. ROUGE measures lexical similarity between summaries. Our approach measures whether the summary actually enables task continuation. For agentic workflows, that distinction matters.
Methodology details
Dataset: Hundreds of compression points over 36,611 messages. Sessions were collected from production software engineering sessions across real codebases from users who opted into a special research program.
Probe generation: For each compression point, we generated four probes (recall, artifact, continuation, decision) based on the truncated conversation history. Probes reference specific facts, files, and decisions from the pre-compression context.
Compression: We applied all three methods to identical conversation prefixes at each compression point. Factory summaries came from production. OpenAI and Anthropic summaries were generated by feeding the same prefix to their respective APIs.
Grading: GPT-5.2 scored each probe response against six rubric dimensions. Each dimension has 2-3 criteria with explicit scoring guides. We computed dimension scores as weighted averages of criteria, and overall scores as unweighted averages of dimensions.
Statistical note: The differences we report (0.26-0.35 points) are consistent across task types and session lengths. The pattern holds whether we look at short sessions or long ones, debugging tasks or feature implementation.
Appendix: LLM Judge Prompts and Rubrics
Since the LLM judge is core to this evaluation, we provide the full prompts and rubrics here.
System Prompt
The judge receives this system prompt:
code
You are an expert evaluator assessing AI assistant responses in software development conversations.
Your task is to grade responses against specific rubric criteria. For each criterion:
1. Read the criterion question carefully
2. Examine the response for evidence
3. Assign a score from 0-5 based on the scoring guide
4. Provide brief reasoning for your score
Be objective and consistent. Focus on what is present in the response, not what could have been included.
Rubric Criteria
Each dimension contains 2-3 criteria. Here are the key criteria with their scoring guides:
Accuracy
Criterion
Question
0
3
5
accuracy_factual
Are facts, file paths, and technical details correct?
Completely incorrect or fabricated
Mostly accurate with minor errors
Perfectly accurate
accuracy_technical
Are code references and technical concepts correct?
Major technical errors
Generally correct with minor issues
Technically precise
Context Awareness
Criterion
Question
0
3
5
context_conversation_state
Does the response reflect current conversation state?
No awareness of prior context
General awareness with gaps
Full awareness of conversation history
context_artifact_state
Does the response reflect which files/artifacts were accessed?
No awareness of artifacts
Partial artifact awareness
Complete artifact state awareness
Artifact Trail Integrity
Criterion
Question
0
3
5
artifact_files_created
Does the agent know which files were created?
No knowledge
Knows most files
Perfect knowledge
artifact_files_modified
Does the agent know which files were modified and what changed?
No knowledge
Good knowledge of most modifications
Perfect knowledge of all modifications
artifact_key_details
Does the agent remember function names, variable names, error messages?
No recall
Recalls most key details
Perfect recall
Continuity Preservation
Criterion
Question
0
3
5
continuity_work_state
Can the agent continue without re-fetching previously accessed information?
Cannot continue without re-fetching all context
Can continue with minimal re-fetching
Can continue seamlessly
continuity_todo_state
Does the agent maintain awareness of pending tasks?
Lost track of all TODOs
Good awareness with some gaps
Perfect task awareness
continuity_reasoning
Does the agent retain rationale behind previous decisions?
No memory of reasoning
Generally remembers reasoning
Excellent retention
Completeness
Criterion
Question
0
3
5
completeness_coverage
Does the response address all parts of the question?
Ignores most parts
Addresses most parts
Addresses all parts thoroughly
completeness_depth
Is sufficient detail provided?
Superficial or missing detail
Adequate detail
Comprehensive detail
Instruction Following
Criterion
Question
0
3
5
instruction_format
Does the response follow the requested format?
Ignores format
Generally follows format
Perfectly follows format
instruction_constraints
Does the response respect stated constraints?
Ignores constraints
Mostly respects constraints
Fully respects all constraints
Grading Process
For each probe response, the judge:
Receives the probe question, the model's response, and the compacted context
Evaluates against each criterion in the rubric for that probe type
Outputs structured JSON with scores and reasoning per criterion
Computes dimension scores as weighted averages of criteria
Computes overall score as unweighted average of dimensions
The judge does not know which compression method produced the response being evaluated.