Engineering
Research
Code Droid: A Technical Report
June 18, 2024 - 12 minute read -
Share
Engineering
Research
June 18, 2024 - 12 minute read -
Share
At Factory, our technical vision is driven by our mission to bring autonomy to software engineering. We are not just building tools; we are building Droids — intelligent, autonomous systems designed to rapidly accelerate software organizations' engineering velocity. Building Droids requires an interdisciplinary approach, drawing from research on how humans and machines make decisions, solve complex problems, and learn from their environments. These systems are designed to model the cognitive processes of human software developers, adapted to the scale and speed that modern software development requires.
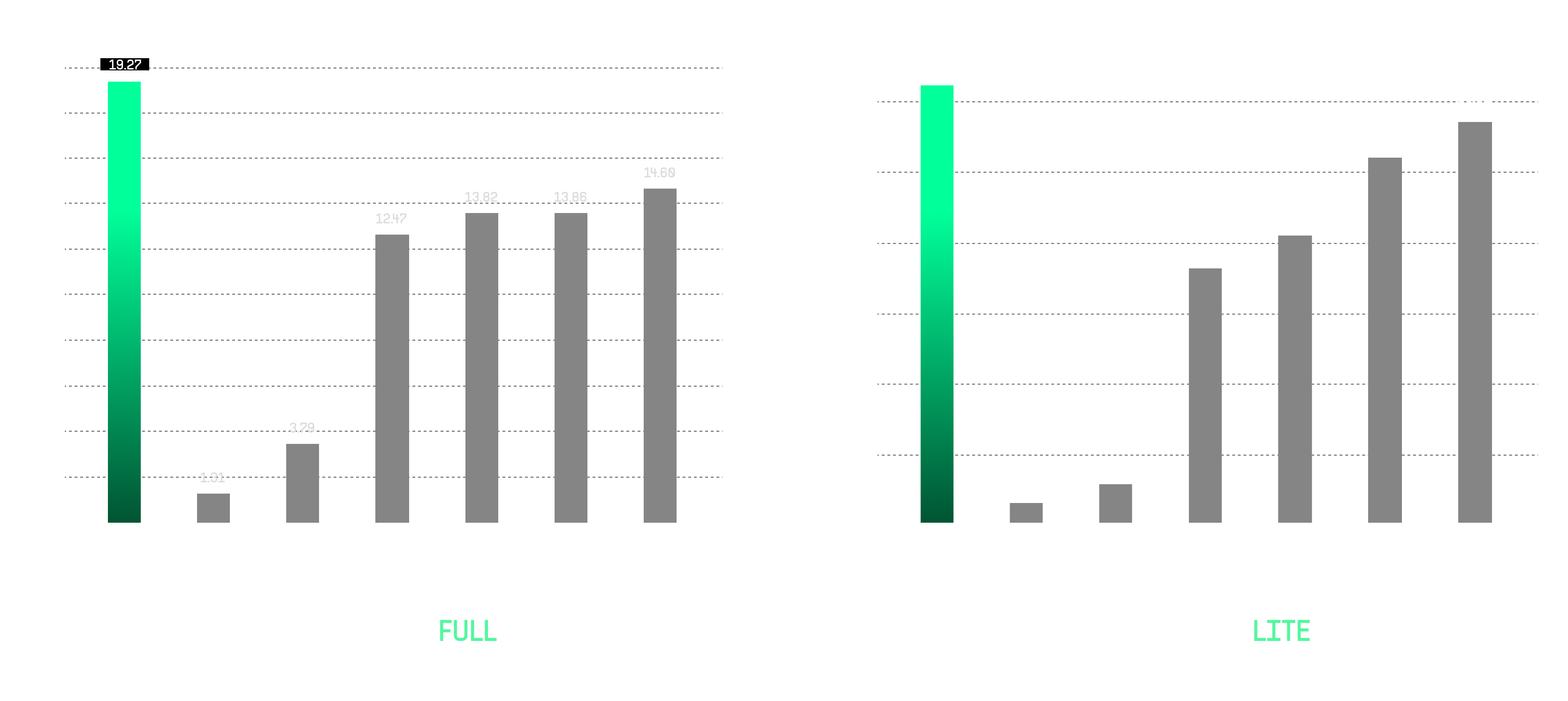
This technical report will give you a high-level overview of the Code Droid. We provide an analysis of its state-of-the-art performance on SWE-bench, where we achieve 19.27% on SWE-bench Full and 31.67% on SWE-bench Lite.
We do not think about performance on a single axis. We are equally focused on the capabilities, safety, and explainability of our systems. Ensuring Droids act reliably and transparently is critical as they take on tasks of increasing complexity — from code review to end-to-end software development — all while securing the intellectual property and operational integrity of the organizations we serve.
We conclude with our vision of the future: one where software development is more efficient, more accessible, and more creative.
Code Droid is designed to execute coding tasks based on natural language instructions. For our customers, its primary function is to automate rote, tedious programming tasks. Common use cases include codebase modernization, feature development, proof-of-concept creation, and building integrations. Here we outline some of the core functionality that we’ve developed to enable it to perform reliably in production environments.
Planning and Task Decomposition
In order to perform complex software development tasks, AI systems require sophisticated multi-step reasoning capabilities. Droids take high-level problems and decompose them into smaller, manageable subtasks. They translate these subtasks into an action space and then reason around optimal trajectories. We have developed several techniques that improve the Droids’ capabilities in reasoning, planning, and subtask decomposition, borrowing ideas from robotics, machine learning, and cognitive science. Droids are able to simulate decisions, perform self-criticism, and reflect on real and imagined decisions. These capabilities enable them to meaningfully guide their path toward optimal trajectories.
Tool Integration and Environmental Grounding
Code Droid has access to many essential tools for software development—from version control systems to editing and debugging tools. We have found it critical to include tools like linters, static analyzers, and debuggers. In general, if a human has access to a tool, so too should Code Droid. The grounding of Code Droid in the environment of a software developer ensures that Code Droid shares the same feedback and iteration loops that human developers use to build software.
HyperCode and ByteRank
Most agentic systems enter a codebase with zero knowledge and must build understanding from scratch. We’ve built a system called HyperCode to construct a multi-resolution representation of a given engineering system that allows Droids to synthesize deep codebase understanding. Droids autonomously construct explicit (graph) and implicit (latent space similarity) relationships within low-level data and extract insights about these relationships at different levels of abstraction. We leverage the insights and data in our retrieval algorithm — ByteRank — to retrieve relevant information for a given task.
Multi-Model Sampling
We’ve found model capabilities to be highly task-dependent. Code Droid leverages different state-of-the-art large language models for different sub-tasks, including the latest models from Anthropic and OpenAI. Code Droid can choose to generate multiple trajectories for a given task, validate them using tests (existing and self-generated), and select optimal solutions from the mix. We have found it beneficial to use a sample of different models during the creation of candidate solutions to ensure diversity and robustness in the final result.
SWE-bench is a benchmark designed to test an AI system’s ability to solve real-world software engineering tasks. It is composed of 2,294 issues and pull requests gathered from twelve popular open-source Python projects. The AI system is given the problem statement extracted from the GitHub issue and the repository itself and is expected to generate a git patch to resolve the issue. The patch is then evaluated against unit tests that verify if the patch resolves the issue.
Setup
Code Droid is set up to autonomously complete tickets assigned to it. For SWE-Bench we took only the problem statement and gave it to Code Droid as a ticket to solve. Importantly, Code Droid did not have access to the hints or the test patch provided by the task. This setup is similar to that of other coding agents. Given the ticket, Code Droid ran until it generated a complete patch, without any human assistance. The patch was then submitted for evaluation.
To guarantee the sanctity of the results, Droid’s access to the internet was revoked. This ensures that Code Droid was not able to search for the solution patch or any other relevant benchmark hints online.
In addition to the above setup, we had to build the HyperCode representation for each codebase and freeze it to the proper commit.
Evaluation
As with other agentic systems, we first revert any changes from Droid’s patch that overlap with the benchmark’s test patch. This is to ensure that the test patch can be applied without issue and the evaluation can be run. We then ran the SWE-Bench evaluation script on the generated patches.
Code Droid did not have any access to hints, internet results, test patches or the oracle patches. To confirm the purity of our results we compared Droid’s patches with the oracle patches. In 39 cases (1.7%), Code Droid’s patch matched the oracle patch exactly. To be extra careful, we modified our criteria to ignore comments, whitespace, and allow for edit distances of less than 10. We found there are 80 cases where Droid’s patch is similar to the oracle patch. Each one of the exact cases involved no more than 3 lines being added and we have manually reviewed each of the close matches to ensure there is no data leakage. In most such cases, the change was either obvious or explicitly requested in the problem statement. We’ve also found that for these patches, other agent’s patches were likely to be exact matches.
We hypothesize that a small number of changes may have benefited from having the underlying language model utilize the same code repositories in its training data. This emphasizes the need for evaluation systems that are private, like our Crucible internal evaluation framework and Scale’s SEAL.
SWE-bench Performance
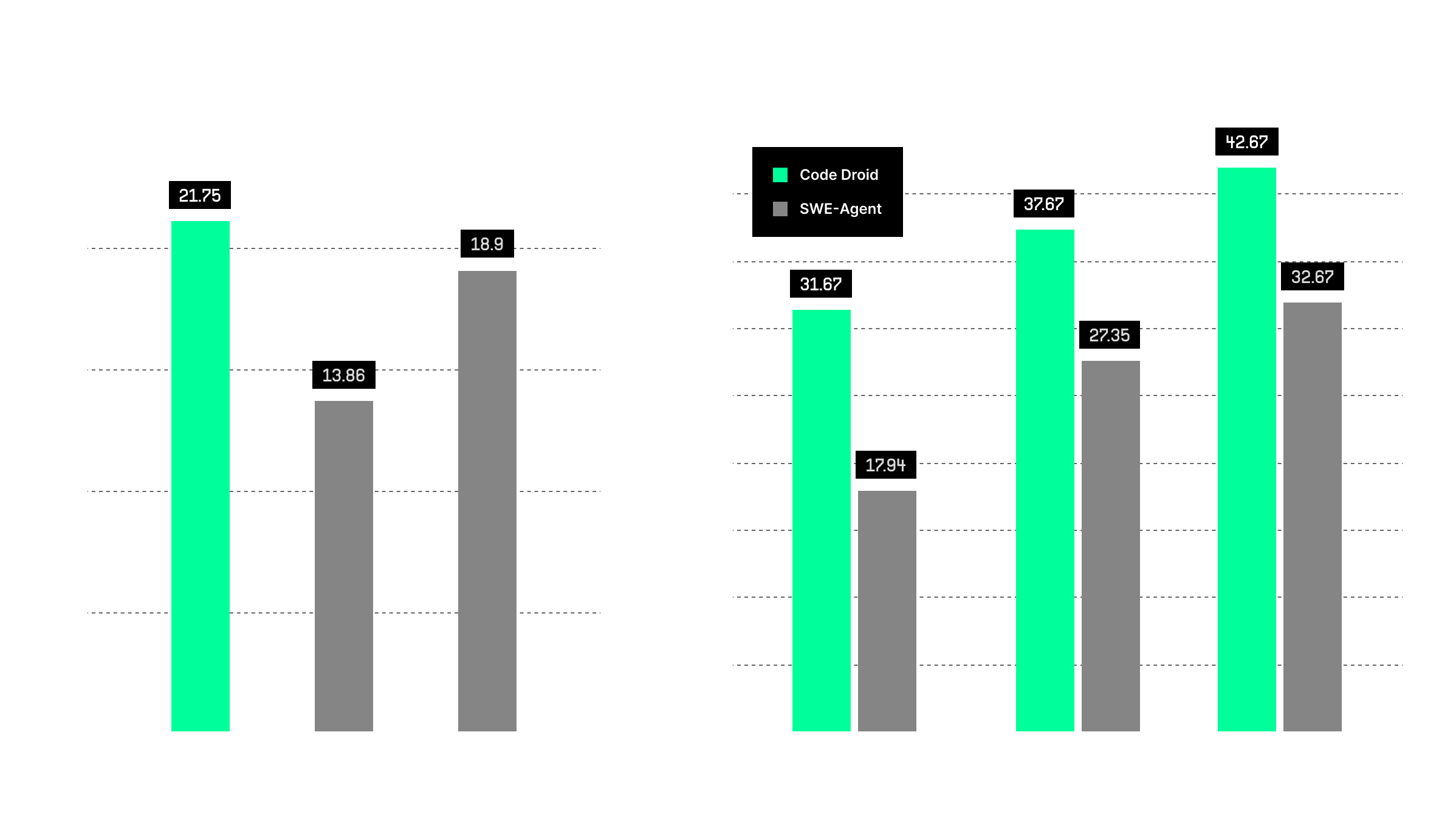
Code Droid demonstrated exceptional performance on the SWE-bench Full benchmark, achieving a score of 19.27%. On the SWE-bench Lite benchmark, Code Droid continued to showcase its strength by achieving a pass rate of 31.67% on the first attempt. This benchmark includes 300 problems, focusing on evaluating the AI system’s ability to solve more straightforward software engineering tasks efficiently. The pass rates improved with multiple attempts - specifically, Code Droid achieved a pass rate of 37.67% pass@2 and further improved to 42.67% for its pass@6.
Analysis on 25% Subset
In a comparative analysis on a subset of SWE-Bench Full, Code Droid was benchmarked against Devin and AiderGPT4o. Code Droid achieved a pass rate of 21.75%, outperforming AiderGPT4o, which had a pass rate of 18.9%, and Devin, which recorded a pass rate of 13.86%. It is crucial to highlight that this subset has a different distribution of problems, potentially leading to higher performance than expected compared to the full benchmark. Thus, we recommend against using this subset as the sole performance indicator.
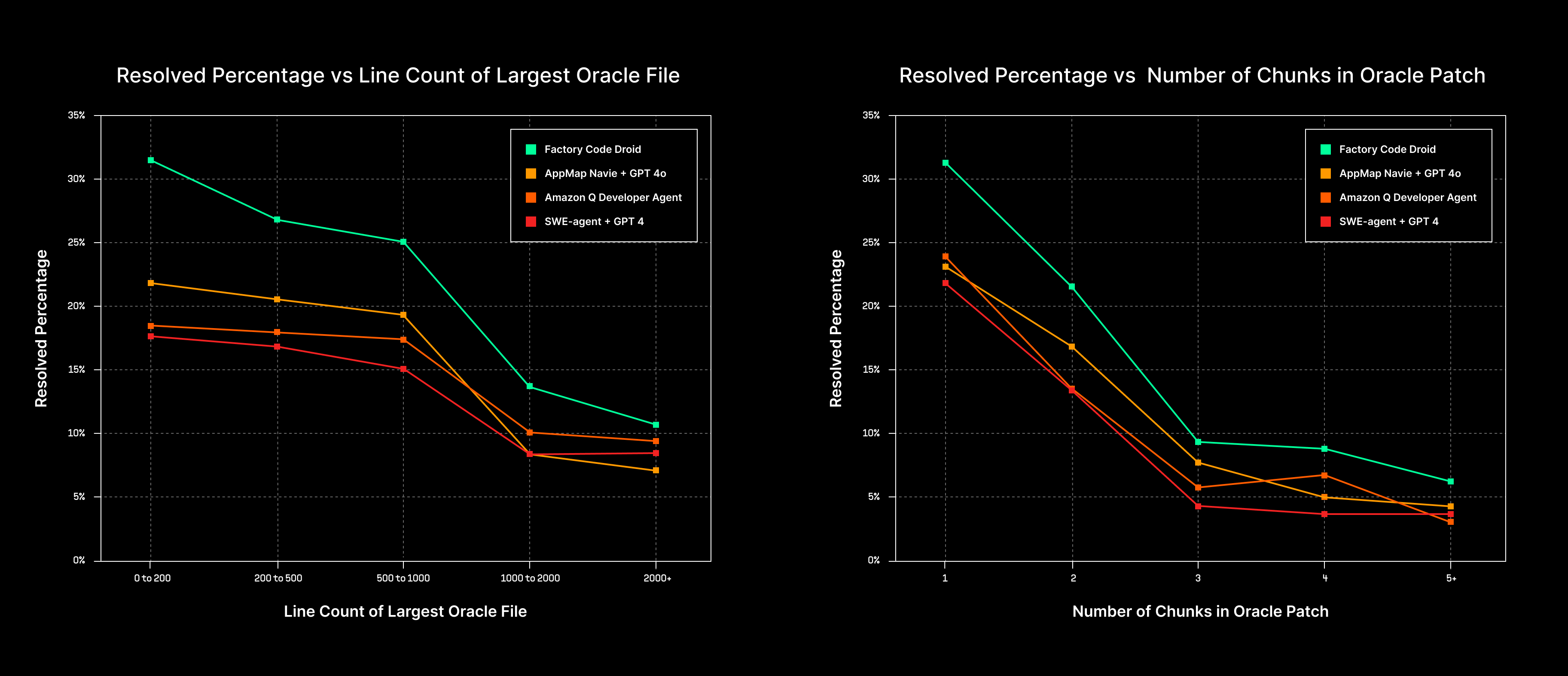
Score Breakdown Based on Task Size
To illustrate Code Droid’s capabilities in handling more simple and more complex tasks we’ve analyzed our success rates relative to the size of the source code file being changed and how many edits in terms of number of diff chunks are required. Code Droid outperforms the competition for both simple and complex tasks. The performance gap is particularly dramatic for smaller and more straight-forward problems, where Code Droid’s advanced reasoning techniques and use of automated tests and tools such as linter helps reduce errors.
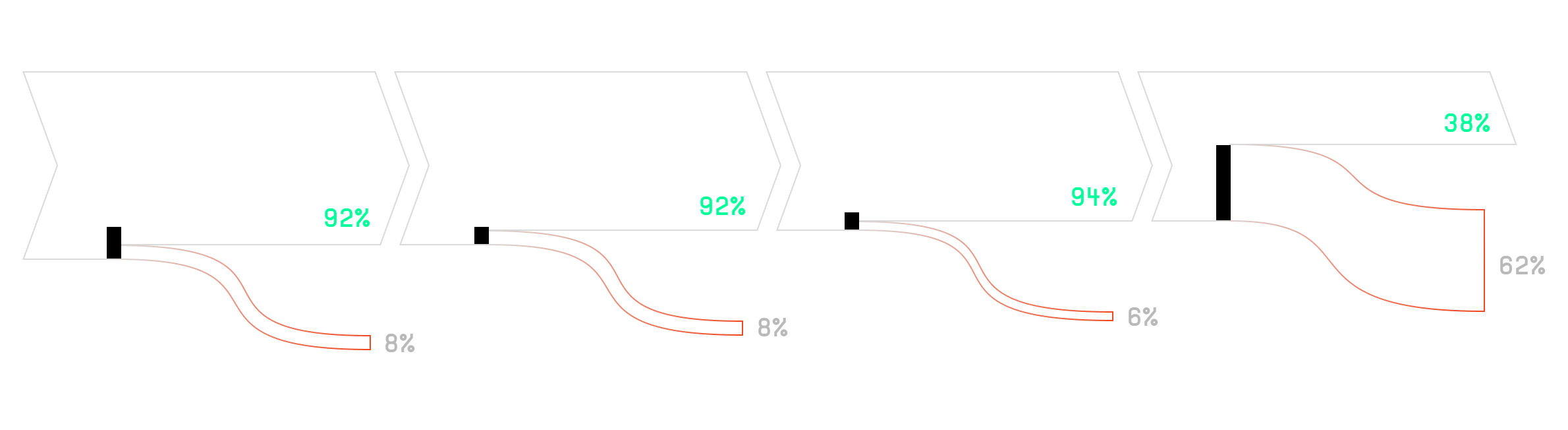
SWE-Bench Lite Failure Modes Analysis
Our analysis of Code Droid’s performance on SWE-bench Lite revealed several points of failure in the system. Notably, in 8% of the tasks, Code Droid failed to include the target file in its list of analyzed files. Additionally, even when the target file was analyzed, it was not prioritized as a top-5 file in another 8% of cases. Further analysis indicated that in 6% of the total cases, the target file, although considered a top priority, was not selected for editing. The remaining failures occurred when the target file was correctly chosen for editing, but the approach taken was incorrect or the instructions were not successfully converted into a passing patch.
Runtime and Token Usage Analysis
The runtime and token usage of Code Droid also presented some variability. On average, Code Droid took between 5 to 20 minutes to generate a single patch, with the system producing up to three patches per task before selecting the most promising one. The most extreme case saw Code Droid taking 136 minutes to generate a patch. In terms of token usage, the runs varied significantly, with some consuming as many as 13 million tokens per patch. However, the average token usage remained under 2 million tokens per patch. It is important to note that no explicit constraints on time or token usage were set during these tests.
SWE-Bench is a fantastic resource for evaluating the software engineering ability of different systems, and we are grateful for its creation. That said, we would be remiss if we did not mention the limitations in the benchmark.
Due to the nature of GitHub issues and the requirements set for data scraping in the SWE-bench paper most, if not all, of the tasks are debugging-style tasks. Tasks where the issue can be described as the code is not behaving as some users would expect and correctness can be evaluated with a unit test. Not all coding tasks are of this style though. Code Droid is designed to handle many types of tasks including migration/modernization tasks, feature implementation tasks, and refactoring tasks.
We also noticed that some tasks could be resolved by editing a different file than the one in the solution patch or by editing a different section of the code in the correct file. Ideally, there would be some way to gauge which patch is better or whether the difference makes a material difference. Judging the quality of a patch is of course difficult, contextual, and imperfect. This limitation is also called out in the original SWE-Bench paper.
We understand that the traditional benchmarks for software engineering automation, while useful, do not fully encapsulate the diversity and complexity of real-world software development tasks that our Droids face. This understanding led us to develop Crucible, Factory’s proprietary benchmarking suite designed to provide a more accurate representation of the challenges Droids are expected to automate in a production environment.
Integrated Realism in Benchmark Design
Crucible isn’t just a single evaluation—it’s a comprehensive framework that integrates complex, real-world software engineering scenarios. Unlike conventional benchmarks which might focus narrowly on task execution, Crucible evaluates Droids across a spectrum of essential capabilities such as code migration, refactoring, integration with APIs, unit-test generation, code review, documentation, and debugging. Each of these tasks is culled from actual development practices and is designed to simulate the genuine demands of a software engineering role.
Customer-Centric Evaluations
One of the unique aspects of Crucible is its alignment with specific customer expectations and enterprise scenarios. Each benchmark is crafted from tasks derived from real industry projects, ensuring that performance metrics correlate directly to practical, deployable benefits in industrial settings. This approach helps us refine Droids in a context that mirrors their eventual operational environments, emphasizing utility and real-world applicability.
Continuous Calibration and Evolution
Crucible is designed to be dynamic. As new technologies emerge and development methodologies evolve, so too does Crucible. This ongoing refinement helps prevent model overfitting to dated or overly specific scenarios, ensuring that our Droids remain versatile and effective across various real-world conditions. Regular updates to the benchmark incorporate emerging trends and technologies, gating Droid development to contemporary standards.
As our autonomous Droids take on increasingly complex roles, the need for them to operate securely and transparently grows. Our approach to these challenges combines rigorous internal controls with clear, communicative interfaces to ensure that developers can understand the actions taken by Droids.
Safety Protocols
Each Code Droid operates within a strictly defined, sandboxed environment that isolates its operational scope from main development environments. This not only prevents unintended interactions that could lead to system destabilization but also ensures the security of the data within the codebases in which they interact. Along with physical and operational isolation, we have enterprise-grade auditing trails and version control integrations to ensure all actions taken by a Droid are traceable and reversible. We also undergo regular penetration tests and have internal red-teaming processes to better understand how complex code generation might work in adverse scenarios.
Explainability by Design
To deepen trust and enable developer oversight, explainability plays a major role in the Droid’s design. Droids log and report the reasoning behind all of their actions. This is a core component of their architecture, ensuring that developers can validate the actions taken by the Droids. Whether it’s a complex code refactor or a routine debugging task, Droids provide clear, logged explanations for their reasoning and decision-making.
DroidShield: Safeguarding Code and IP
We also introduce DroidShield, our internal algorithm designed to enhance the safety of code manipulation by the Droids. DroidShield performs real-time static code analysis to detect potential security vulnerabilities, bugs, or intellectual property breaches before they are committed to code. This preemptive identification process reduces the risk associated with automated code edits and ensures alignment with industry best practices and compliance standards.
Societal Responsibility
Recognizing the rapidly evolving landscape of AI ethics, Factory is committed to leading discussions on societally responsible AI use in software development. We are proactively setting up frameworks and policies that not only align with current standards but also anticipate future regulatory landscapes and societal expectations. We are currently one of the first organizations globally to be certified with ISO 42001 - the leading international standard for secure and forward thinking AI management systems. Factory’s commitment to security is further solidified by our adherence to multiple industry compliance standards like SOC 2, ISO 27001 and 42001, GDPR, CCPA, and more. These certifications and independent audits demonstrate our ongoing dedication to managing data in a way that ensures security and respects privacy.
As we look toward the future of software engineering, our focus remains on expanding the capabilities of the Droids, empowering developers, and addressing the evolving needs of a rapidly moving industry. To continue our trajectory, we are exploring several exciting avenues in enhancing the capability and functionality of Droids.
Advanced Cognitive Architectures
Building more sophisticated cognitive frameworks remains a central pillar of our research effort. By diving deeper into systems that mimic human cognitive processes, we can give Droids even greater ability to handle ambiguous and complex software challenges with nuanced and context-aware responses. These architectures will lean heavily on the latest advancements in machine learning, cognitive science, and robotics, crafting systems that not only solve problems but understand them deeply. To this end, we believe there are several frontier challenges:
Enhanced Tool Integration and Utilization
The effective use of tools defines expert software engineering just as much as coding proficiency. We aim to further enhance our Droids' ability to interact with and leverage a broader array of development tools and environments. This includes integrating more sophisticated static analysis tools, development tooling, frameworks, and more reliable interactions with cloud-based infrastructure. The goal is to create a genuinely versatile Droid that adapts tools to tasks dynamically and intelligently. Some ideas were interested in here include:
Fine-Tuning and Hyper-Specialization
As software development continues to specialize, there arises a need for Droids tailored to specific domains. Factory is exploring the deployment of Droids specialized for fields such as AI development, embedded systems, financial services, and more. Each of these fields presents unique challenges and requires specialized knowledge that our targeted Droids will embody. Some interesting questions here:
Infrastructure for Large-scale Deployment
Deploying Droids across various environments at scale requires robust infrastructure and smooth operational frameworks. Our team is dedicated to scaling the underlying systems that support Droid deployment, ensuring that they are reliable, secure, and capable of handling diverse and intensive engineering tasks without lag or loss of functionality. Some problems we’re interested in:
Open Collaboration and Ecosystem Growth
Finally, we are fostering an ecosystem where developers, companies, and researchers can collaborate openly on advancing Droid technology. This includes open-source initiatives, partnerships with academic institutions, and engagement in global tech communities. By sharing knowledge and tools, we plan to enhance the collective capability to address some of the most pressing and exciting challenges in software engineering.
In embracing these directions, Factory is not just adapting to change—we are seeking to drive it. Our vision extends beyond merely enhancing productivity; we aim to transform how software is conceptualized, created, and optimized, broadening the scope and impact of software engineering across all sectors of society.
As we continue to push forward the frontier of AI in software development, we realize that the future of software engineering demands not just technological expertise but a fusion of insights from diverse fields like neuroscience, math, physics, social sciences, and, of course, software engineering itself. If you are interested in joining us in our mission of bringing autonomy to software engineering - you can apply to open roles at https://factory.ai/careers.
We’d like to acknowledge a few sources of inspiration:
start building
Start building

